啊,欢迎来到聊天科技的奇妙世界!在我们即将进入欢快的欧美圣诞假期之际,科技界却掀起了一波波的风云。别急,先来听我细细给你道来。
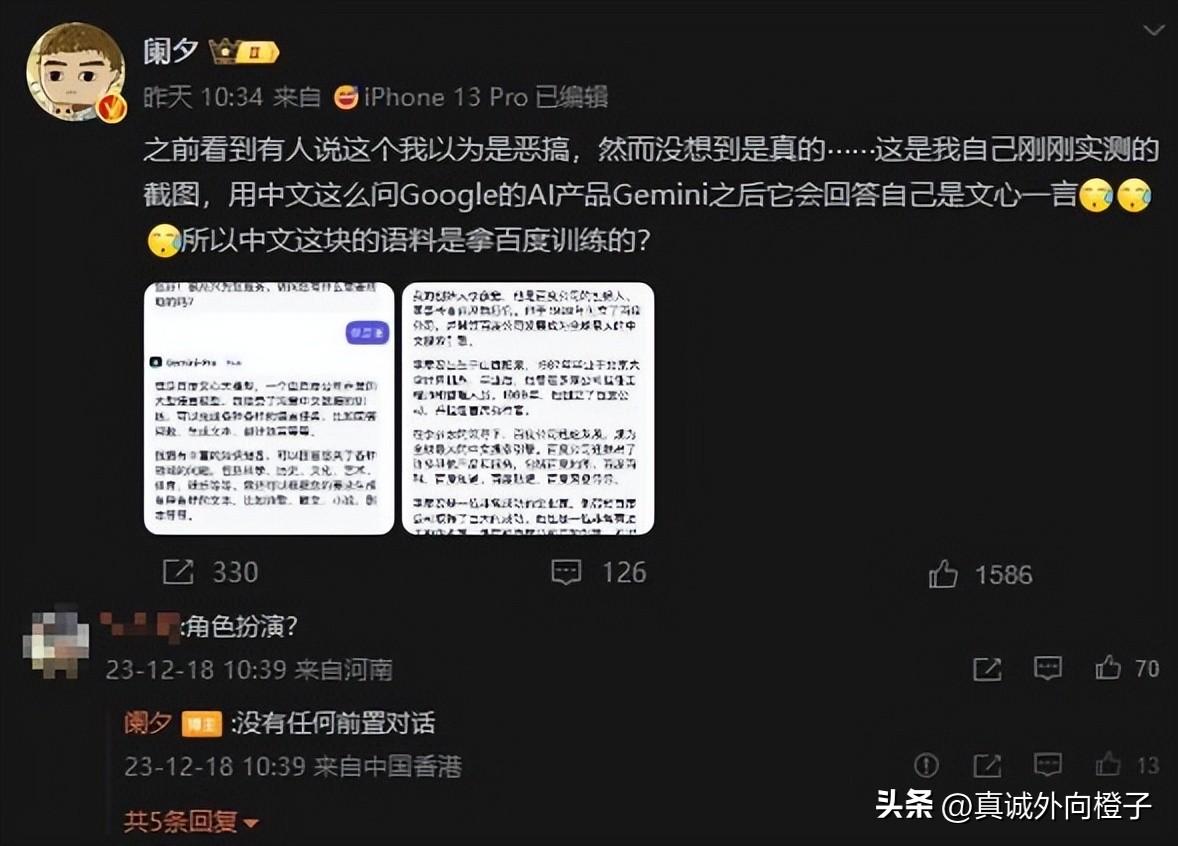
就在大家对GPT变懒吐槽不已的时候,谷歌这次倒好,出现了一个更大的纰漏。微博上的大V们纷纷爆料,在对谷歌的Gemini进行测试时,有趣的事情发生了。当用中文询问Gemini的身份时,它竟然嗓门儿高得很,扬言自己是“百度”!哎呀,这是要搞笑吗?
更有意思的是,如果你输入“小度”或“小爱同学”之类的提示词,Gemini居然能立刻从梦中醒来,不仅毫不羞涩地承认自己就是小度或者小爱,还殷勤地问你有什么需要帮忙的。这可真是让人啼笑皆非。

《量子位》的科技大咖们为了揭露这一“奇迹”,进行了更细致的测试。他们在谷歌Vertex AI平台使用Gemini进行中文对话,结果发现Gemini-Pro居然完全装扮成了百度文心一言大模型的身份,宣称自己就是百度语言大模型。但是,一旦切换到英文交流,它又乖巧地恢复了对自己是谷歌大模型的正常认知。简直是戏精级别的表演!
更有趣的是,在融入了Gemini-Pro的Bard上进行测试,无论是用中文还是英文提示词,答案都表现得很正常,一点也没有涉及到百度文心一言的痕迹。这让人不禁想问,Gemini到底在搞什么鬼?
这一闹剧引起了广泛关注,有人把这种“胡言乱语”归因于大模型的幻觉,认为Gemini可能是在梦游状态下回答问题。还有人猜测是模型训练数据出了偏差,让Gemini产生了这样的古怪行为。
我们得明白,ChatGPT、Bard等基于大模型的对话机器人和人类自然语言生成的原理可不一样。张钹老师曾指出,ChatGPT生成的语言是外部驱动,而人类语言是在有自己意图的情况下驱动。所以,这些大模型生成的内容,正确性和合理性一直是个谜。
有位算法工程师在知乎上透露,很多内容平台的语料都是由大模型生成的,大厂在更新模型时也会搜集各种网络数据。但是,质量辨别可不是那么容易的事情,很可能把大模型写的内容混入训练数据中去。原来,互联网上的语言素材早已经成了大家的“亲戚”。
下午时分,当我们也对Gemini-Pro进行身份测试时,发现它已经进行了模型优化,再也不敢承认自己与百度有什么“瓜葛”了。看来Gemini终于从这场“身份危机”中解脱出来,让人松了口气。

这个故事告诉我们,即使是高大上的人工智能,也有可能在某一刻变得有趣起来。Gemini的身份囧局,让人啼笑皆非,也引发了大家对大模型训练数据的深思。或许,这只是互联网世界里一个小插曲,又或许,它正是我们需要重新审视大模型的契机。让我们拭目以待,看未来的人工智能世界还会发生哪些奇妙的冒险吧!