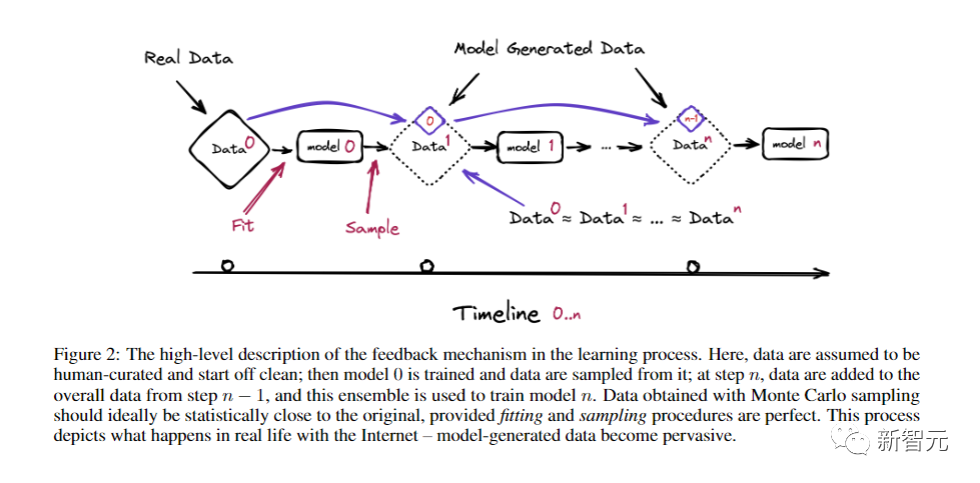
在下图中,假设人工整理的数据开始是干净的,然后训练模型0,并从中抽取数据,重复这个过程到第n步,然后使用这个集合来训练模型n。通过蒙特卡洛采样获得的数据,在统计意义上最好与原始数据接近。
这个过程就真实地再现了现实生活中互联网的情况——模型生成的数据已经变得无处不在。
此外,互联网语料被污染还有一个原因——创作者对于抓取数据的AI公司的抗争。
在今年早些时候,就有专家警告说,专注于通过抓取已发布内容来创建AI模型的公司,与希望通过污染数据来捍卫其知识产权的创作者之间的军备竞赛,可能导致当前机器学习生态系统的崩溃。
这一趋势将使在线内容的构成从人工生成转变为机器生成。随着越来越多的模型使用其他机器创建的数据进行训练,递归循环可能导致「模型崩溃」,即人工智能系统与现实分离。
贝里维尔机器学习研究所(BIML)的联合创始人Gary McGraw表示,数据的退化已经在发生——
「如果我们想拥有更好的LLM,我们需要让基础模型只吃好东西,如果你认为他们现在犯的错误很糟糕,那么,当他们吃自己生成的错误数据时又会发生什么?」
GPT-4耗尽全宇宙数据?全球陷入高质量数据荒
现在,全球的大模型都陷入数据荒了。
高质量的语料,是限制大语言模型发展的关键掣肘之一。
大型语言模型对数据非常贪婪。训练GPT-4和Gemini Ultra,大概需要4-8万亿个单词。
研究机构EpochAI认为,最早在明年,人类就可能会陷入训练数据荒,那时全世界的高质量训练数据都将面临枯竭。
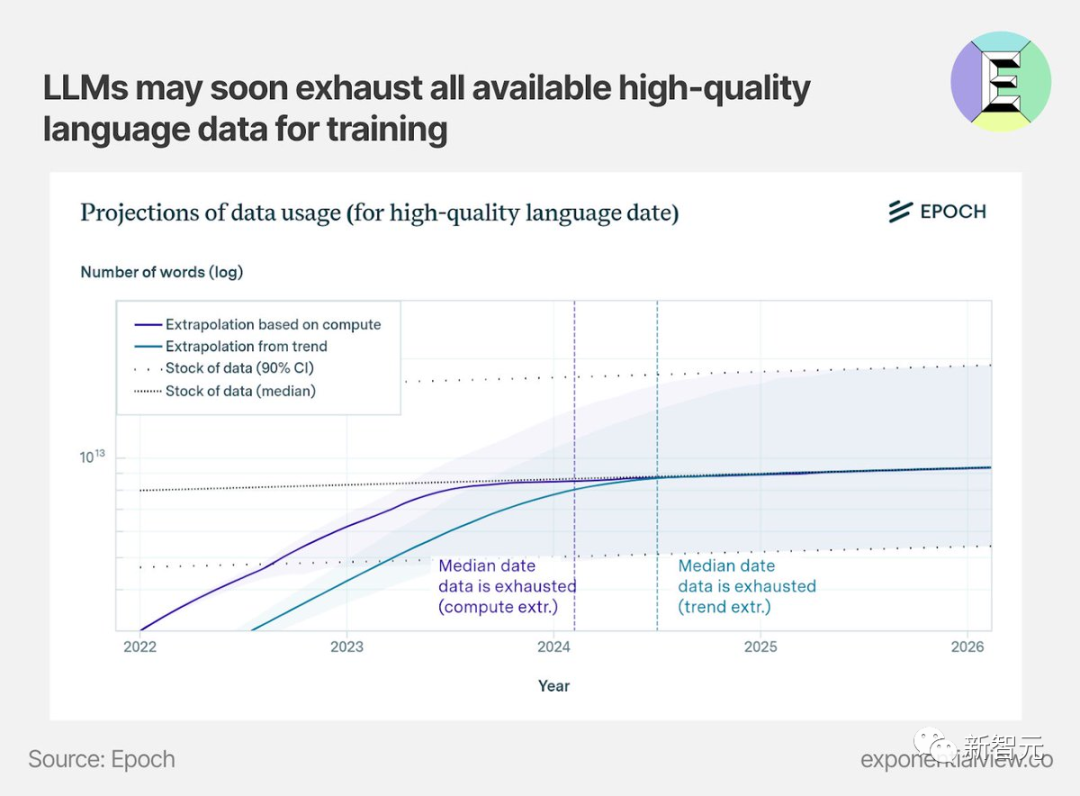
去年11月,MIT等研究人员进行的一项研究估计,机器学习数据集可能会在2026年之前耗尽所有「高质量语言数据」。

论文地址:https://arxiv.org/abs/2211.04325
OpenAI也曾公开声称自己数据告急。甚至因为数据太缺了,接连吃官司。
今年7月,著名UC伯克利计算机科学家Stuart Russell称,ChatGPT和其他AI工具的训练可能很快耗尽「全宇宙的文本」。
现在,为了尽可能多地获取高质量训练数据,模型开发者们必须挖掘丰富的专有数据资源。

最近,Axel Springer与OpenAI的合作就是一个典型例子。
OpenAI付费获得了Springer的历史和实时数据,可以用于模型训练,还可以用于回应用户的查询。
这些经过专业编辑的文本包含了丰富的世界知识,而且其他模型开发者无法获取这些数据,保证了OpenAI独享的优势。
毫无疑问,在构建基础模型的竞争中,获取高质量专有数据是非常重要的。
到目前为止,开源模型依靠公开的数据集进行训练还能勉强跟上。
但如果无法获取最优质的数据,开源模型就可能会逐渐落后,甚至逐渐与最先进的模型拉开差距。
很早以前,Bloomberg就使用其自有的金融文件作为训练语料库,制作了BloombergGPT。

当时的BloombergGPT,在特定的金融领域任务上超越了其他类似模型。这表明专有数据确实可以带来差异。
OpenAI表示愿意每年支付高达八位数的费用,以获取历史和持续的数据访问权限。
而我们很难想象开源模型的开发者们会支付这样的成本。
当然了,提高模型性能的方法不仅限于专有数据,还包括合成数据、数据效率和算法改进,但看起来专有数据是开源模型难以跨越的一道障碍。