谷歌在 12 月 6 日发布了 Gemini 语言大模型,并在 Bard 中上线了 Gemini Pro 版本。谷歌同时在官网发布了 Gemini 的详细技术报告(),对于 Gemini 的训练原理和测试等进行了详细解释。
到底如何理解 Gemini 的原生多模态能力?
以及从现在的报告数据来看,Gemini 的能力和 GPT-4 相比,差距有多大?
我们选取了两位相关行业技术专家对于这份技术报告、Gemini 产品演示视频的分析,在 Gemini Ultra 未发布之前,提供更多角度的解读。
Founder Park 已获取两位作者授权转载。
李博杰
Gemini 真实能力相比 GPT-4 应该有一定差距
现在连 Google 都开始刷榜了
刚刚跟我们 co-founder 讨论了下,他是 evaluation 的老手,印证了我的猜测。
首先跟 GPT-4 对比的时候,竟然是自己用 CoT,GPT-4 用 few-shot,这本身就不公平。CoT(思维链)可以显著提升推理能力。有没有 CoT 的区别,就好像考试的时候一个人允许用草稿纸,另一个人只允许口算。
更夸张的是,用了 CoT@32,也就是每个问题回答 32 次,选出其中出现次数最多的那个答案作为输出。也就是说明 Gemini 的幻觉很严重,同一个问题回答准确率不高,所以才需要重复回答 32 次选出现次数最多的。生产环境中真要这么搞,成本得多高呀!

其次是用了未对齐的模型跟已经对齐的 GPT-4 做对比。GPT-4 报告里面已经说了模型对齐会降低知识方面的能力,但是提升推理能力。之前我们用 GPT-3.5 未对齐的内部版本做测试,发现可以知道中科大某个教授教了哪门课这种级别的细节,但公开发布的已对齐版本就只能知道中科大的校长是谁了。所以用未对齐的 Gemini 和已对齐的 GPT-4 对比也是不太公平的。
Gemini 的真实能力肯定是远超 GPT-3.5 的,肯定是个比较靠谱的模型,但是相比 GPT-4 估计还有差距。
目前 Gemini 还没有公布定价,如果 Ultra 模型的定价是 GPT-3.5 的量级,那么它的能力显然是比 GPT-3.5 更强的,值得用。但是如果定价类似 GPT-4,那么可能还是 GPT-4 更实用一些。
视频理解:实时性比准确性更重要
Gemini 视频理解的能力不错,演示视频很酷炫。但可惜的是这个视频是剪辑出来的,实际的 Gemini 根本达不到演示视频的实时性。
其实这个演示视频中的效果 GPT-4V 也能做出来,只要把截图喂给 GPT-4V 这些任务就都能完成了(生成图片的任务可以转成文本再接图片生成模型),当然 GPT-4V 的延迟比较高,做不到 Gemini 这个视频里这么实时。我还没有用过 Gemini 的 API,不知道实际延迟会不会比 GPT-4V 更低。
一些比较小的模型,比如 Fuyu-8B 和 MiniGPT-v2,也能做到这个演示视频中大部分的效果,这些任务都是 VQA 里面相对基本的。这些小的开源模型还有个优势,从图片输入到首个 token 输出的延迟只有 100-200 ms,可以做到这个演示视频里面的实时效果。图片生成方面,stable diffusion 20 个 step 肯定达不到这个演示视频里的时延,需要用 SDXL Turbo 或者 LCM 这些最新的模型才能做到。
从用户体验角度看,toC 场景下实时性其实是比准确率更重要的。比如语音识别,虽然 OpenAI 的 Whisper API 准确率是很高的,VITS 合成的声音也比较自然,但是语音识别和语音合成目前都是以整句为单位进行的,即使按照句子切片做识别和合成,一个语音对话系统的端到端时延(从用户说话结束到 AI 开始说话)高达 5 秒左右,这是用户难以忍受的。Whisper 和 VITS 原生都不支持类似同声传译的 streaming。要想做到 2 秒以内的语音延迟,还是需要很多工程优化的。
以后发布的支持语音通话的产品,可以拿 Gemini 这个演示视频作为一个参考标准,达到这个交流的流畅程度就非常好了。Google 暂时还没做到的实时性,哪家公司率先做到了,就是竞争力。
Nano 模型:看起来不太理想
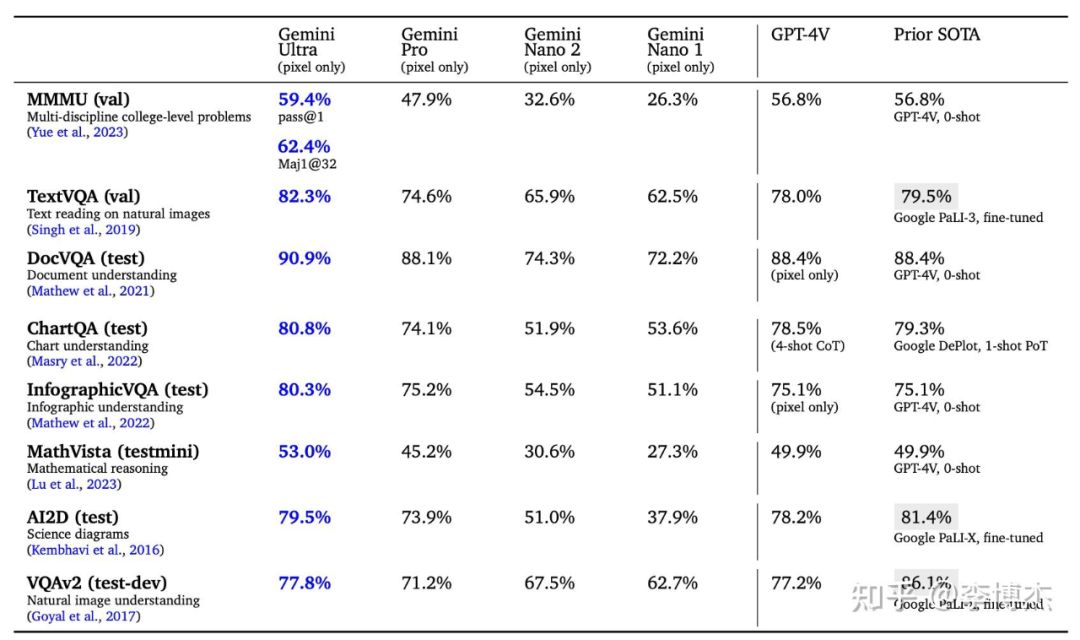
Nano 模型值得关注,1.8B 和 3.25B 的模型,还是 4-bit 量化的,内存占用只有大约 1 GB 和 2 GB,在大多数手机和 PC 上都可以跑起来。但是从评测报告的得分上看起来并不是特别理想,不知道实际用起来效果如何。这个评测报告上面大量的 SOTA 宣称是 Google PaLI-X,它在真实场景中的表现其实是不如 GPT-4V 的,评测报告中也说了 PaLI-X 是 fine-tuned,因此 PaLI-X 也有刷榜的问题。
李博杰:中科大与 MSRA 联培计算机博士,AI 创业者
原文链接:https://www.zhihu.com/question/633684692/answer/3316416317
张俊林
文本可能是大模型获取知识的主要来源渠道
如果仔细分析技术报告,结论很可能是这样的:在数学逻辑等基础学科能力上来看,Gemini Ultra 可能不如 GPT-4,多模态能力上应该强于 GPT-4V。
技术报告要点提炼
技术报告 60 页,没有透漏具体技术细节,大部分是评测,技术报告作者列表包含 9 页内容,超过 700 人,应该接近 OpenAI 的员工总数了吧。
Gemini 是几种模态一起联合从头训练的,包括文本、图片、音频、视频等。这与目前通常的多模态做法不太一样,目前的多模态模型一般是使用现成的语言大模型或者经过预训练过的图片模型(比如 CLIP 的图片编码部分),然后利用多模态训练数据在此基础上加上新的网络层训练;如果是几个模态从头开始一起训练,那么按理说应该都遵循 next token prediction 的模式,就应该是 LVM 的那个路子,其它模态的数据打成 token,然后图片、视频等平面数据先转换成比如 16*16=256 个 token,然后搞成一维线性输入,让模型预测 next token,这样就把不同模态在训练阶段统一起来。
技术报告说应该是 Decoder only 的模型结构,针对结构和优化目标做了优化,优化目的是大规模训练的时候的训练和推理的稳定性,所以大结构应该是类似 GPT 的 Decoder-only 预测 next token prediction 的模式。目前支持 32K 上下文。
Gemini Nano 包含两个版本:1.8B 面向低端手机,3.25B 面向高端手机。文章说 Nano 首先从大模型蒸馏,然后 4bit 量化。我这里有个问题:为什么不用手机调用 API 的方式调用服务端的最强模型呢?能想到的一个可能的解释是用户隐私,这样手机不用把数据传到云端;另外一个推理成本从云端转移到了手机,能够大量节省推理成本。还有其他原因么?我一直不太理解为何要做塞到手机里的大模型,不确定核心优点是什么。
从硬件描述部分来看,意思是动用了前所未有的 TPU 集群,所以推测 Gemini Ultra 的模型规模应该相当大,猜测如果是 MOE 大概要对标到 GPT-4 1.8T 的模型容量,如果是 Dense 模型估计要大于 200B 参数。考虑到引入视频音频(当然是来自于 Youtube 了,难道会来自 TikTok 么)多模态数据,所以总数据量*模型参数,会是非常巨大的算力要求,技术报告说可以一周或者两周做一次训练。
训练可能分成多个阶段,最后阶段提高了领域数据的混合配比,猜测应该指的是逻辑和数学类的训练数据增加了配比,目前貌似很多这么做的,对于提升模型逻辑能力有直接帮助。
看学科能力测试,技术报告指标有人为拔高的倾向,比如 MMLU,从 32 次测试里投票选择最优答案,而对比的 GPT-4 则仅从 5 个测试里进行投票,这个对比明显不公平。当例子数量都减少到 5 个,Gemini Ultra 得分 83.7%,不如 GPT-4 得分 86.4%,高于 GPT-3.5 的 70%。从测试具体情况看,gemini ultra 应该是和 GPT-4 基本持平或者稍微弱于 GPT-4 的,Gemini Pro 和 Ultra 差距比较大,应该略微强于 GPT-3.5;而且 Llama2 在数学、推理等方面与最好的大模型效果差距非常明显,不同测试指标差距 20 到 40 分之间;
从学科能力测试数据看,目前大模型能力很可能顺序如下:GPT-4 略微强于 Geminni Ultra> Claude 2> inflection-2> GPT-3.5= Grok 1 >Llama2。
AlphaCode2 是在 Gemini Pro 基础上,使用编程竞赛的数据 fine-tune 出来的,效果提升很明显,在编程竞赛上排名超过 85% 的人类选手,之前的 AlphaCode1 超过 50% 的人类选手;
Gemini Ultra 在多模态能力方面,在几乎所有测试数据上确实要比 GPT-4V 强一些。
命令理解方面:和 GPT 一样,采用多模态 instruct 数据进行 SFT+RM+RLHF 三阶段,这里的 RM 部分在训练打分模型的时候,采用了加权的多目标优化,三个目标 helpfulness factuality 和 safety,猜测应该是对于某个 prompt,模型生成的结果,按照三个指标各自给了一个排序结果。
一个悲观的结论
最后多说一句,从 Gemini 能够推断出一个悲观的结论如下:
因为在 GPT-4V 前大多数是文本模型,很多人觉得文本模型缺乏 Grounding,就是文本抽象语义和真实物理对象对应不起来,大模型理解不了物理世界的知识,而视频数据那么多,如果引进了后,大模型不仅能建立起 grounding,更重要的是视频数据蕴含了比文本更多的知识,所以对大模型的知识储备会有极大的增长。这里可能存在误解。
从 Gemini 的效果来看,事实可能并非如此,Gemini 多模态效果不错,它主打多模态,肯定引入了尽量多的视频、图片信息,这一方面说明多种模态联合训练确实有用,但是它的用处主要在于:把文本抽象概念和物理实体形象的对应 Grounding 建立起来了,但是在大模型的世界知识和各种能力储备方面,经过大量视频强化过的 Gemini 甚至可能还比不过只用文本训练的 GPT-4。
这一切指向如下可能:就世界知识含量来说,文本是大模型获取知识的主要来源渠道,视频、图片数据在这方面对于文本的世界知识补充作用微乎其微,视频、图片和文本多模态训练的主要作用是建立起实体概念及知识抽象表述和外在物理形象绑定建立 grounding 而已。除此外,无需对类似视频等多模态数具有更高的期望。
本质上,目前多模态大模型效果还不错,是大模型把从文本中学到的世界知识和逻辑能力,经过 grounding 绑定到实体外在形象后,在多模态场景下语言模型把丰富的世界知识迁移给了多模态模型,是文本模型带着多模态在飞,而不是反过来。