OpenAI的GPT-4V和谷歌最新的Gemini多模态大语言模型一经推出就得到业界和学界的热切关注: 一系列工作都从多角度展示了这些多模态大语言模型对视频的理解能力。人们似乎相信我们离通用人工智能artificial general intelligence (AGI) 又迈进了一大步!
可如果告诉你,GPT-4V连漫画中的人物行为都会看错, 试问:元芳,你怎么看?
我们来看看这幅迷你漫画系列:

如果让生物界最高智能体——人类,也就是读者朋友来描述, 你大概率会说:

那我们来看看当机器界最高智能体——也就是GPT-4V来看这幅迷你漫画系列的时候,它会这么描述呢?

GPT-4V作为公认的站在鄙视链顶端的机器智能体,居然公然睁眼说瞎话。
还有更离谱的是,就算给GPT-4V实际的生活图像片段,它也会把一个人上楼梯过程中与另一个人交谈的行为也离谱的识别成两个人手持「武器」相互打斗嬉闹 (如下图所示)。

Gemini也不遑多让,同样的图像片段,把这个过程看成了男子艰难上楼并与妻子争吵被锁在屋里。

这些例子都来自于马里兰大学联合北卡教堂山的研究团队的最新成果,他们推出了一个专门为MLLM设计的图像序列的推理基准测试——Mementos。
就像诺兰的电影《Memento记忆碎片》重新定义了叙事方式,Mementos正在重塑测试人工智能的上限。
作为一个全新的基准测试,它挑战的是人工智能对如记忆碎片般的图像序列的理解。

论文链接:https://arxiv.org/abs/2401.10529
项目主页:https://mementos-bench.github.io
Mementos是第一个专为MLLM设计的图像序列推理的基准测试,主要关注大模型在连续图像上的对象幻觉和行为幻觉。
其涉及的图片类型多样,涵盖三大类别:真实世界图像,机器人图像,以及动漫图像。
并且包含了4,761个不同长度的多样化图像序列,每个序列都配有人类注释的主要对象及其在序列中的行为描述。
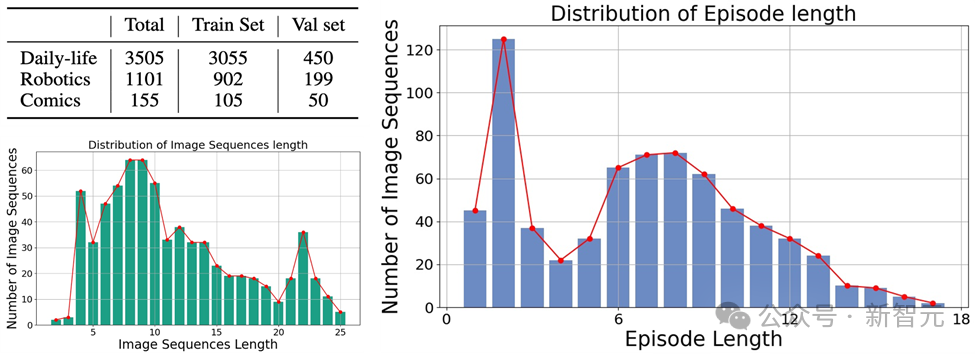
目前数据已经开源,并且还在更新中。
幻觉类型
作者在论文中阐述了MLLM在Mementos中会产生的两种幻觉:对象幻觉(object hallucination)和行为幻觉(behavior hallucination)。
顾名思义, 对象幻觉是幻想出不存在的对象(object), 而行为幻觉则是幻想出对象并没有做出的动作与行为。
测评方式
对于如何准确的评估MLLM在Mementos上的行为幻觉和对象幻觉,研究团队选择了将MLLM产生的图像描述和人标注的描述进行关键词匹配。
为了自动化评测每一个MLLM的表现,作者采用了GPT-4辅助测试的方法来进行评估:
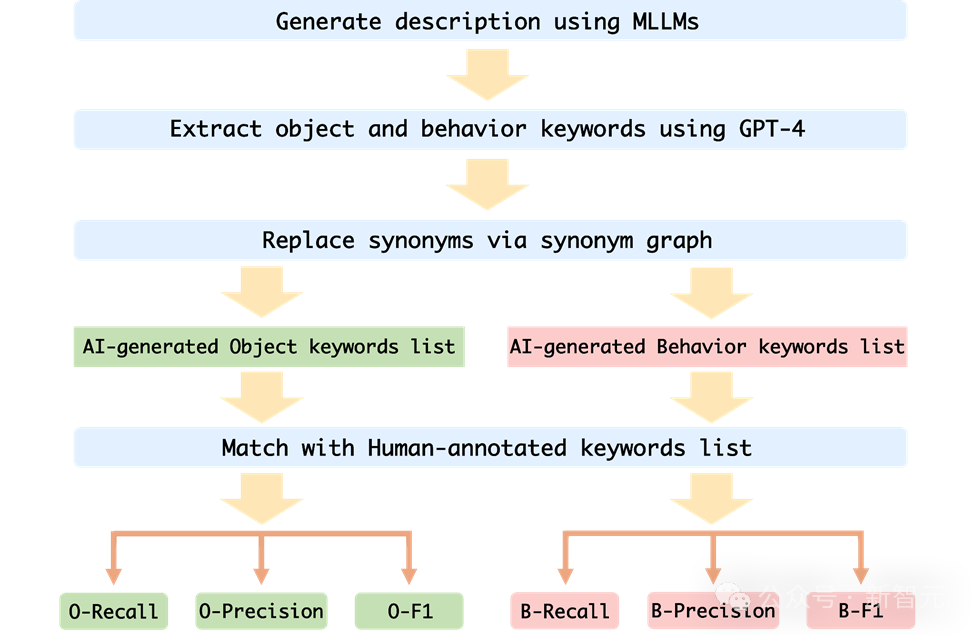
1. 作者将图像序列和提示词作为输入给MLLM,并生成与相应图像序列对应的描述;
2. 请求GPT-4提取AI生成描述中的对象和行为关键词;
3. 获得两个关键词列表:AI生成的对象关键词列表和AI生成的行为关键词列表;
4. 计算AI生成的对象关键词列表和行为关键词列表和人的标注的关键词表的召回率、准确率和F1指标。
测评结果
作者在Mementos上评估了MLLMs在序列图像推理方面的表现,对包括GPT4V和Gemini在内的九种最新的MLLMs进行了细致的评估。
MLLM被要求来描述图像序列中正在发生的事件,从而来测评MLLM对于连续图像的推理能力。
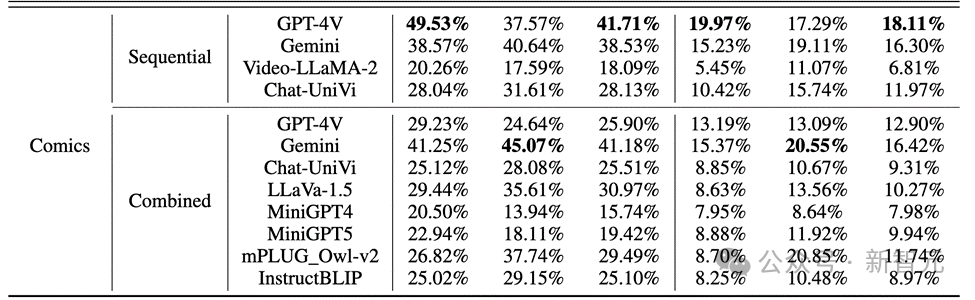
结果发现,如下图所示,GPT-4V和Gemini对于人物行为在漫画数据集的正确率竟然不到20%。
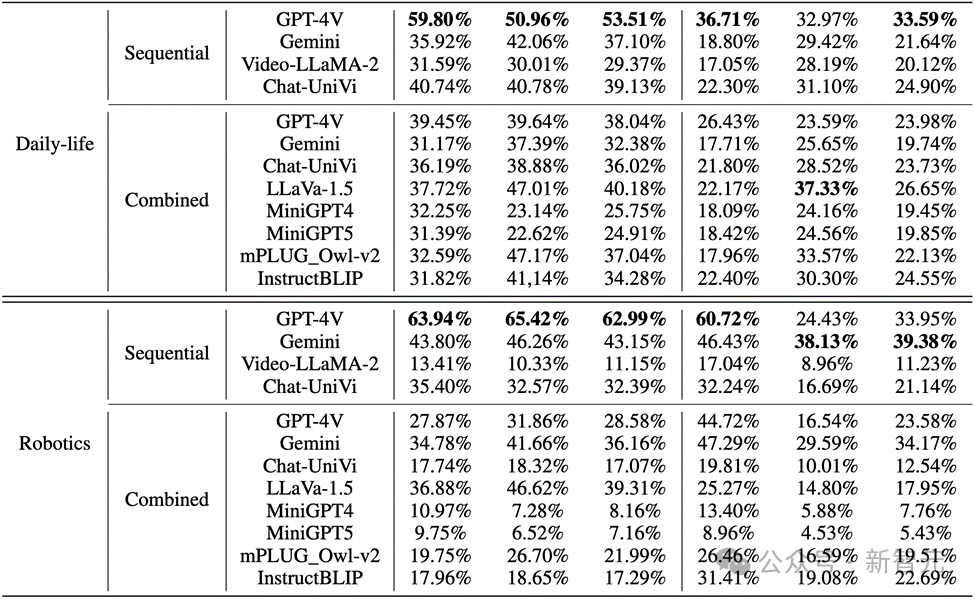
而在真实世界图像和机器人图像中,GPT-4V和Gemini的表现也不尽如人意:
关键点
1. 在评估多模态大型语言模型时,GPT-4V和LLaVA-1.5分别是在黑盒和开源MLLMs中表现最好的模型。GPT-4V在理解图像序列方面的推理能力优于其他所有MLLMs,而LLaVA-1.5在对象理解方面几乎与黑盒模型Gemini相当或甚至超越。
2. 虽然Video-LLaMA-2和Chat-UniVi是为视频理解设计的,但它们并没有显示出比LLaVA-1.5更好的优势。
3. 所有MLLMs在图像序列中对象推理的三个指标上表现显著优于行为推理,表明当前MLLMs在从连续图像中自主推断行为的能力不强。
4. 黑盒模型在机器人领域的表现最佳,而开源模型在日常生活领域表现相对较好。这可能与训练数据的分布偏移有关。
5. 训练数据的局限性导致开源MLLMs的推理能力较弱。这表明了训练数据的重要性以及它对模型性能的直接影响。
错误原因
作者对当前多模态大型语言模型在处理图像序列推理时失败的原因的分析,主要识别了三个错误原因:
1. 对象与行为幻觉之间的相互作用
研究假设,错误的对象识别会导致随后的行为识别不准确。量化分析和案例研究表明,对象幻觉会在一定程度上导致行为幻觉。例如,当MLLM错误地将场景识别为网球场后,可能会描述人物正在打网球,即使这种行为在图像序列中并不存在。
2. 共现对行为幻觉的影响
MLLM倾向于生成在图像序列推理中常见的行为组合,这加剧了行为幻觉的问题。例如,在处理机器人领域的图像时,MLLM可能错误地描述一个机器人手臂在“抓取把手”之后拉开抽屉,即使实际行为是“抓取抽屉的侧面”。
3. 行为幻觉的雪球效应
随着图像序列的进行,错误可能会逐渐累积或加剧,这称为雪球效应。在图像序列推理中,如果早期出现错误,这些错误可能会在序列中积累和放大,导致对象和行为识别的准确性下降。
举个例子

从上图可知,MLLM失败原因包括对象幻觉以及对象幻觉与行为幻觉之间的相关性,以及共现行为。
例如,在出现「网球场」的对象幻觉后,MLLM随后展现出「拿着网球拍」的行为幻觉(对象幻觉与行为幻觉之间的相关性)以及「似乎在打网球」的共现行为。

观察上图中的样本,可以发现MLLM错误地认为椅子再往后仰并且认为椅子碎掉了。
这一现象揭示了MLLM对于图像序列中的静止的对象,它也会产生这个对象发生了某些动作的幻觉。

在上图关于机械臂的图像序列展示中,机械臂伸到了把手旁边,MLLM就错误地认为机械臂抓住了把手,证明了MLLM会生成在图像序列推理中常见的行为组合,从而产生幻觉。

在上图的案例中,老夫子并没有牵着狗,MLLM错误地认为遛狗就要牵着狗,并且「狗的撑杆跳」被识别成了「创造了喷泉」。
大量的错误反映了MLLM对于漫画领域的不熟悉,在二次元动漫领域,MLLM可能需要大幅度的优化和预训练.
在附录中,作者通过详细展示了各主要类别中的失败案例,并进行了深入的分析。
总结
近年来,多模态大型语言模型在处理各种视觉-语言任务上展现出了卓越的能力。
这些模型,如GPT-4V和Gemini,能够理解和生成与图像相关的文本,极大地推动了人工智能技术的发展。
然而,现有的MLLM基准测试主要集中于基于单张静态图像的推理,而对于从图像序列中推断,这对于理解我们不断变化的世界至关重要,的能力研究相对较少。
为了解决这一挑战,研究人员提出了一种新的基准测试「Mementos」,目的是评估MLLMs在序列图像推理方面的能力。
Mementos包含了4761个不同长度的多样化图像序列。此外,研究团队还采用了GPT-4辅助方法来评估MLLM的推理性能。
通过对九个最新的MLLMs(包括GPT-4V和Gemini)在Mementos上的仔细评估,研究发现这些模型在准确描述给定图像序列的动态信息方面存在挑战,常常导致对象及其行为的幻觉/误表达。
量化分析和案例研究识别出三个关键因素影响MLLMs的序列图像推理:
1. 对象和行为幻觉之间的相关性;
2. 共现行为的影响;
3. 行为幻觉的累积影响。
这一发现对于理解和提升MLLMs在处理动态视觉信息方面的能力具有重要意义。Mementos基准不仅揭示了当前MLLMs的局限性,也为未来的研究和改进提供了方向。
随着人工智能技术的快速发展,MLLMs在多模态理解领域的应用将变得更加广泛和深入。Mementos基准测试的引入,不仅推动了这一领域的研究,也为我们提供了新的视角,去理解和改进这些先进的AI系统如何处理和理解我们复杂多变的世界。