Gemini 1.5的发布在AI社区引发了不小的轰动,它实现了一百万token的上下文窗口,有些人认为这会对RAG相关的研究与开发产生不利影响。然而,本文认为Gemini 1.5恰恰代表了RAG的积极发展,它凸显了RAG的核心优势,即可以以非黑盒的方式优化成本、准确性及延迟。仅依赖Gemini 1.5是无法做到这一点的。
Medium:Why Gemini 1.5 (and other large context models) are bullish for RAG
Gemini 1.5的第一个明显缺点是成本和延迟,这也上是企业级RAG系统面临的一个难题。
成本
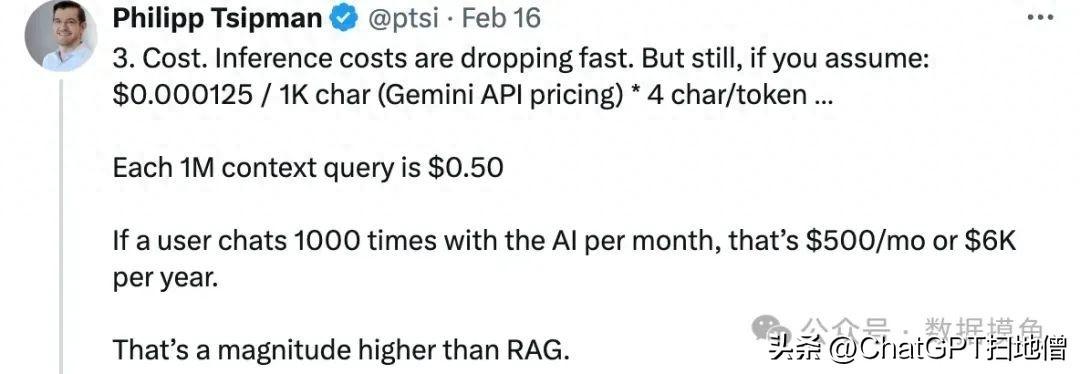
推文内容:推理成本正在快速下降,但如果假设每一千个字符的成本为0.000125美元(这是Gemini API的价格),每个token占4个字符。每一百万次上下文查询的费用为0.5美元。如果用户每月与AI聊天1000次,那么成本就是500美元,每年6000美元,这比RAG高出一个数量级。

Gemini Pro 1.5与RAG在长文本情况下的成本对比,RAG方案成本明显低于Gemini 1.5。
延迟

推文内容:36万上下文时,Gemini通常需要约30秒的时间生成回复,而60万上下文则需要1分钟,大约每秒对应1万token。它还远远无法取代RAG
对于目前采用LLM进行信息检索的企业来说,使用Gemini 1.5的”蛮力”全上下文窗口方法不太可能成为将应用程序投入生产的方法。
准确性
尽管有媒体称Gemini 1.5可以在100万上下文窗口下运行良好,但谷歌的论文却显示了在上下文中使用如此多token时的定量问题。下图是要求模型从一段文本中检索出几个给定的句子的测试。召回率是指他们能够在给出的信息中找出给定句子的成功率。
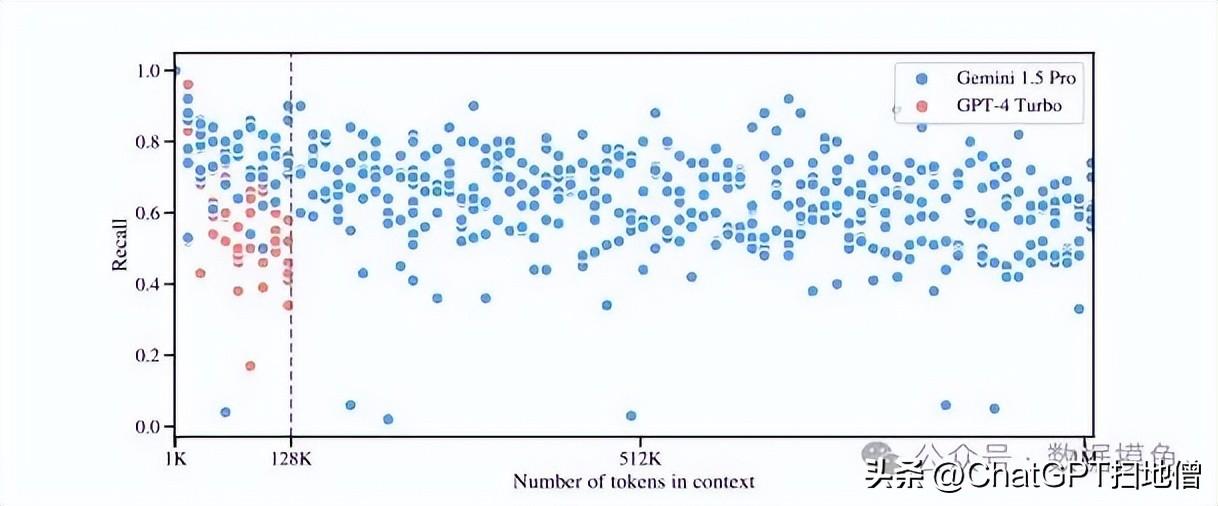
从图表中可以看出,虽然Gemini 1.5比GPT-4 Turbo更好(在上下文窗口重叠范围内),而且Gemini可以一直保持100万个token的召回能力,但平均召回率徘徊在60%左右。上下文窗口可能充满了许多相关事实,但其中40%或更多的事实被模型”丢失”了。如果想确保模型确实使用了您发送的上下文,最好先对其进行整理,然后只发送最相关的上下文。换句话说,就是进行传统的RAG。
对于生产中的系统来说,40%的人无法识别上下文中的句子是不可靠的,尤其是需要确保准确的答案时。Gemini 1.5在找出一个句子和找出多个句子方面的成功率截然不同。现实世界中的问题往往比”为我找出这个句子”更复杂,即使使用Gemini,也很难通过大语境窗口召回答案。
给LLM提供过多不相关的信息客观上是有害的,而目前距离LLM能够保证它们能够处理抛给它们的所有信息还很远。此外,还不清楚这些基准是否适用于现实世界中的各种情况。
Gemini的性能
随着时间的推移,谷歌和Gemini最终会成为基础模型领域的主要竞争者之一。然而,Gemini 1.5技术论文只在测试中将自己与GPT-4进行了比较。
在文本、视觉、音频等其他基准测试中,值得注意的是,Gemini没有将自己与GPT-4进行比较,而是将自己与旧版本的Gemini进行比较。这让人怀疑,这些与GPT-4相比的结果之所以没有展示,是因为它们表现并不好。
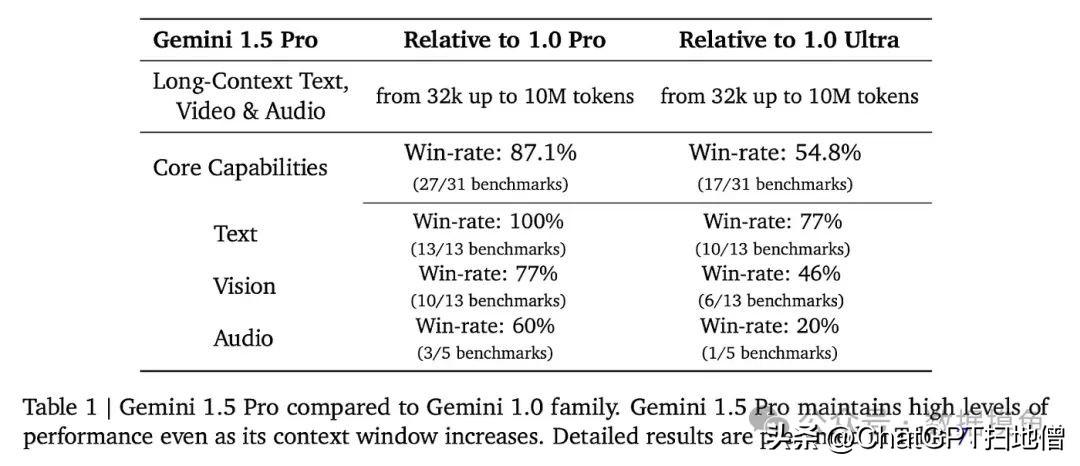
Gemini 1.5 Pro和Gemini 1.0系列的对比
为什么看好RAG
当复杂的RAG仍需要更好的系统来获取原型时,Gemini无法扼杀RAG: 像Gemini 1.5中那样的长上下文窗口可提高RAG系统的精确度,允许进行不那么精确的检索,但却能进行有意义的处理。这有助于更轻松地生产RAG,解决当前基础设施不足的问题,加快开发速度,最终增强RAG应用。目前仍需要更多像Gemini这样的基础模型来支持生产型RAG。
最终状态:让我们想象一下这样一个世界,一个真正可靠的大上下文窗口模型已经出现。假设所有公司都采用了这种模型,他们会希望进一步降低成本,减少延迟。开发人员最常说的一句话是:”我们希望以GPT3.5的成本获得GPT-4的性能”。模型成本是生产的真正障碍,开发人员正在努力对其进行优化。
如何降低成本并减少延迟?他们的办法是尽量减少发送到上下文窗口的信息量。这就是RAG。从根本上说,RAG是一个信息优化过程,有助于减少发送到模型中的无关信息量。如果能向模型提供更多相关信息,即使是当今最强大的模型也能从更高的准确性中获益。RAG很可能是一种持久的机制,特别是对于复杂的RAG系统。