谷歌憋了许久的大招,双子座Gemini大模型终于发布!其中一图一视频最引人注目:
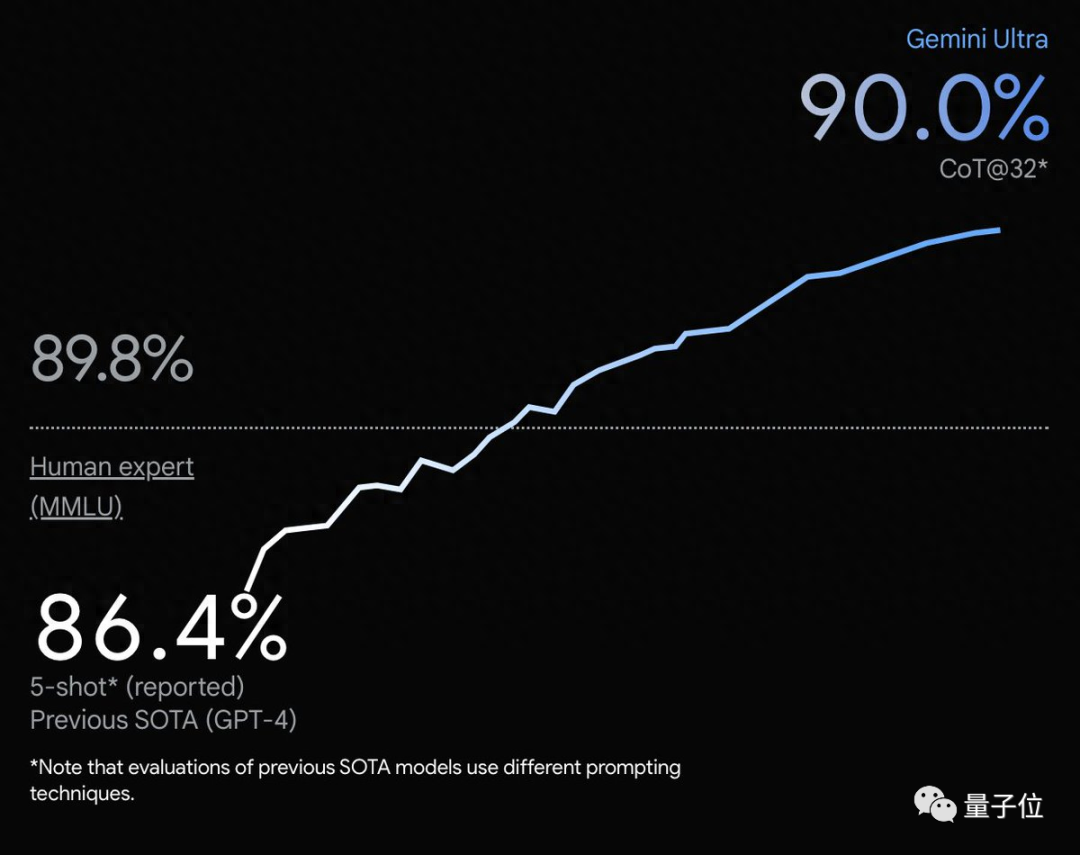
一图,MMLU多任务语言理解数据集测试,Gemini Ultra不光超越GPT-4,甚至超越了人类专家。
一视频,AI实时对人类的涂鸦和手势动作给出评论和吐槽,流畅还很幽默,最接近贾维斯的一集。

然鹅当大家从惊喜中冷静下来,仔细阅读随之发布的60页技术报告时,却发现不妥之处。
(没错,没有论文,OpenAICloseAI你开了个什么坏头啊)
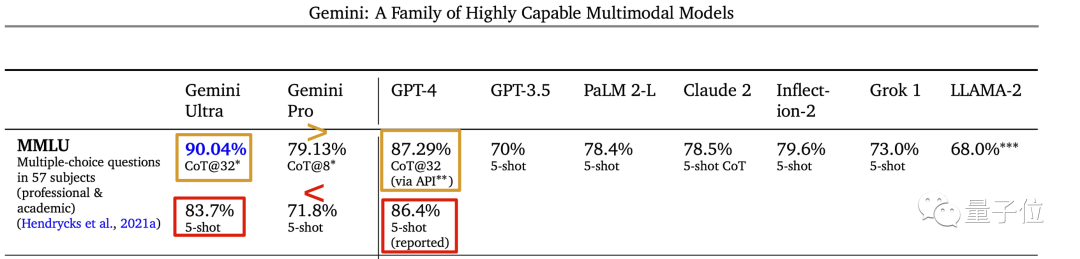
MMLU测试中,Gemini结果下面灰色小字标称CoT@32,展开来代表使用了思维链提示技巧、尝试了32次选最好结果。
而作为对比的GPT-4,却是无提示词技巧给5个示例,这个标准下Gemini Ultra其实并不如GPT-4。

以及原图比例尺也有点不厚道了,90.0%与人类基准89.8%明明只差一点,y轴上却拉开很远。
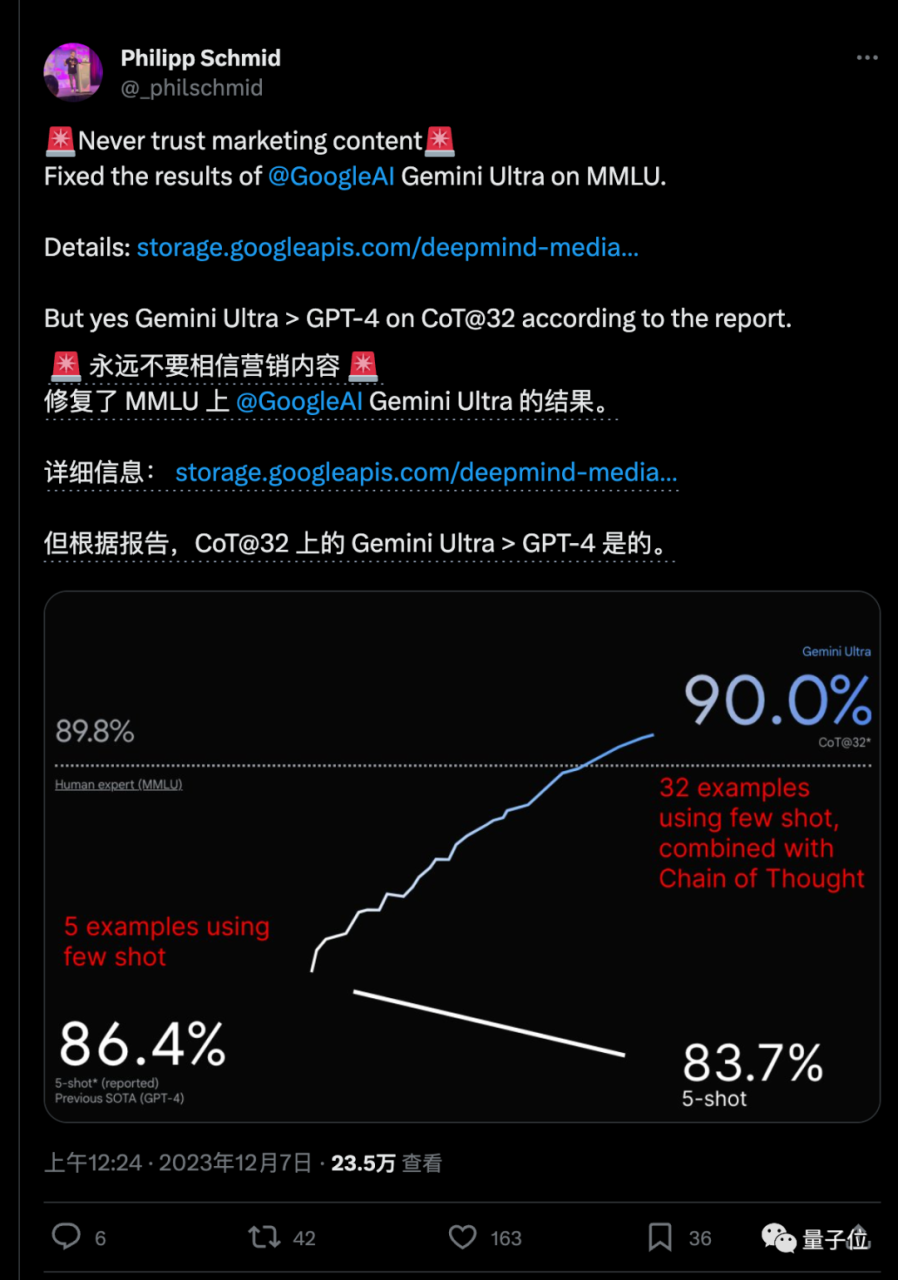
HuggingFace技术主管Philipp Schmid用技术报告中披露的数据修复了这张图,这样展示更公平恰当:
每到这种时候,总少不了做表情包的老哥飞速赶到战场:

但好在,同样使用思维链提示技巧+32次尝试的标准时,Gemini Ultra还是确实超越了GPT-4的。
Jeff Dean在一处讨论中对这个质疑有所回应,不过大家并不买账。

另外,对于那段精彩视频,也有人从开篇的文字免责声明中发现了问题。
机器学习讲师Santiago Valdarrama认为声明可能暗示了展示的是精心挑选的好结果,而且不是实时录制而是剪辑的。