谷歌最强大模型Gemini 1.5 Pro今天起,“全面”对外开放。
目前完全免费,开发者可以通过API调用的方式使用,普通玩家也可以在谷歌AI Studio中直接体验。
(Ps. 发布这则消息的谷歌工程师Logan Kilpatrick正是原来OpenAI开发者关系的负责人,刚刚跳槽到谷歌。)
最让人期待的是,Gemini 1.5 Pro API首次增加了音频理解功能。
无论是财报电话会、电视节目还是大神演讲,不需要我们再提供字幕文档它就可以直接解读了。

如下图所示:
上传Jeff Dean长约117000+token的演讲录音,Gemini 1.5 Pro在30.8s内就完成了解析。
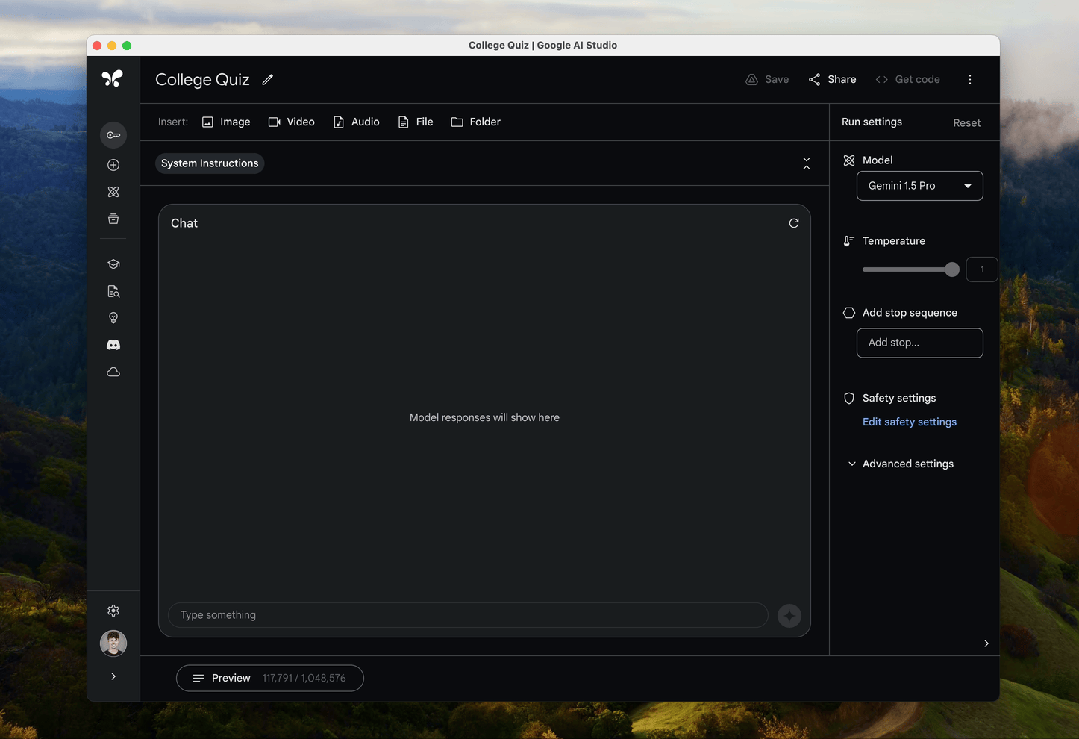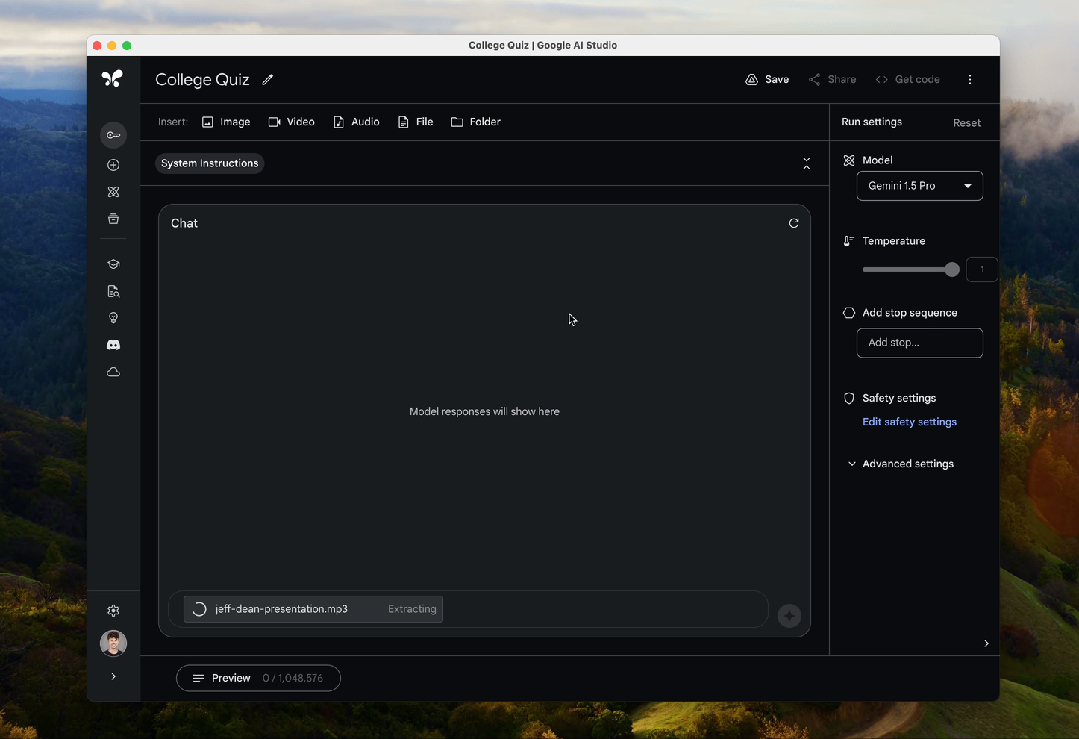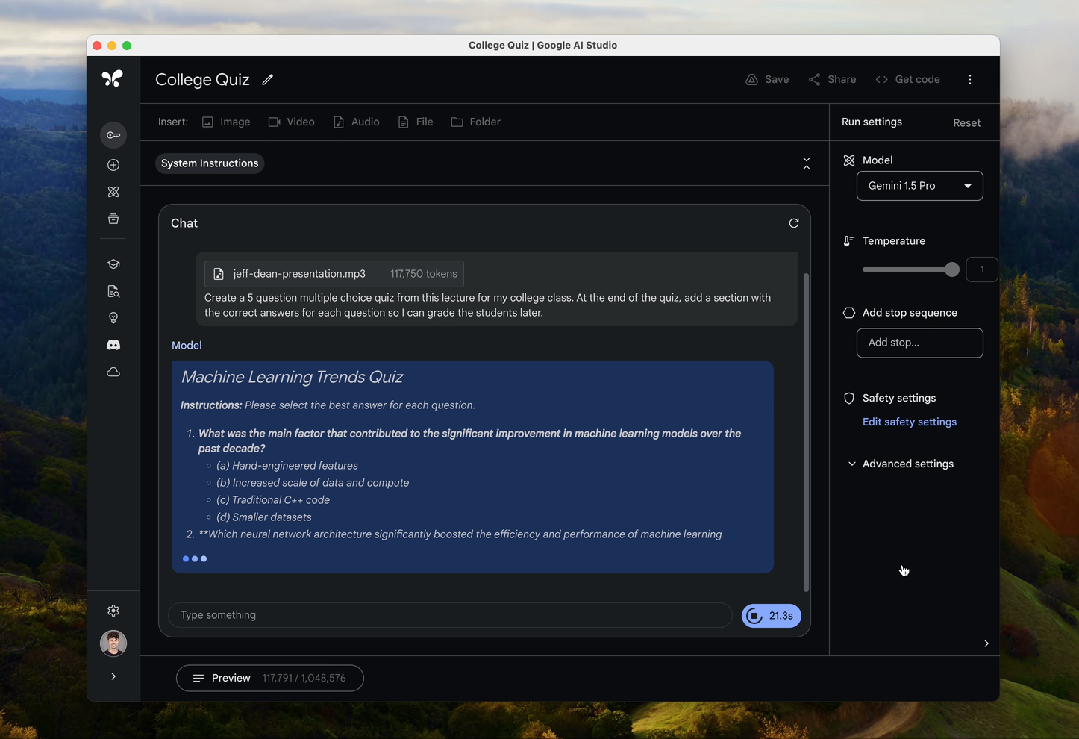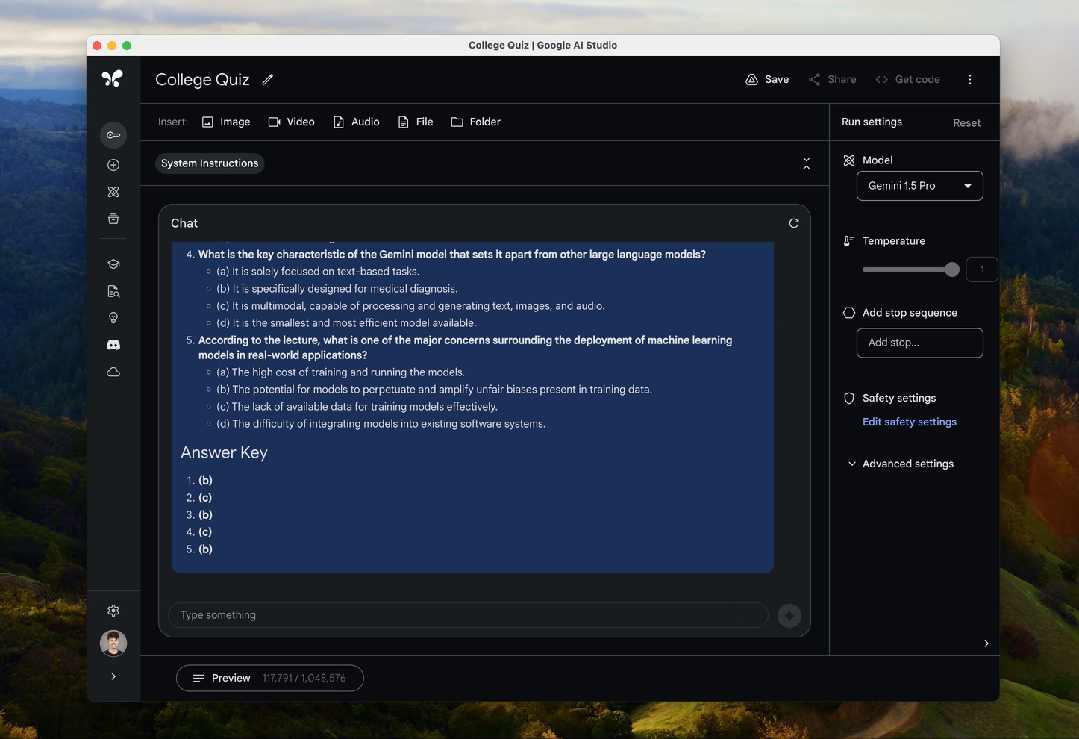
而由于Gemini 1.5 Pro100万的上下文窗口这次也直接对外开放,因此它可以处理的最长音频约为11小时,最长视频则为1小时,相当够用。
我们也赶紧实测了一把,结果是真香。
Gemini 1.5 Pro开放API了
谷歌官方给这次免费开放的Gemini 1.5 Pro版本定义为“公开预览版”。
它主要面向开发者,可在谷歌AI Studio中获得API密钥:
目前最引人注目的音频理解功能还没添加到API中,但据说很快就会补上。
问题不大,我们可以先在Google AI Studio中直接体验:
在实测中,我们上传了比尔盖茨1995年做客Late Show节目的一段音频,时长1分钟。
我们没有提示这段音频的任何背景信息,Gemini 1.5 Pro直接就听出来了是谁。
并在10s左右精准整理出了全对话的精华部分,一点“正确的废话”都没有:
表现令人折服。
接下来,来个更具挑战的,Andrej Karpathy1小时长的大模型科普教程。
我们提取音频文件,足足10万多个token(这种在UI里直接显示当前消耗token数量的方法也广受好评)。