AI大模型向多模态发展已经是个趋势,因其能理解和生成图像、文本等多种信息形式而备受瞩目。但是目前还没有一个开源AI大模型集成识别图像和生成的图像的功能,而刚刚由港大贾佳亚团队发布的开源多模态AI模型Mini-Gemini,不仅能理解图像,还能根据指令生成图片,甚至还能读懂梗图、复现数学函数,堪称开源版的“GPT-4 + DALL-E 3”。
图像识别能力比肩顶尖商业闭源模型
我用微软的一个AI知识点手绘图,分别测试 ChatGPT-4、Gemini 1.5 pro、Claude3-Opus目前最好的三个闭源商业模型跟Mini-Gemini对比。

Mini-Gemini-34B-HD
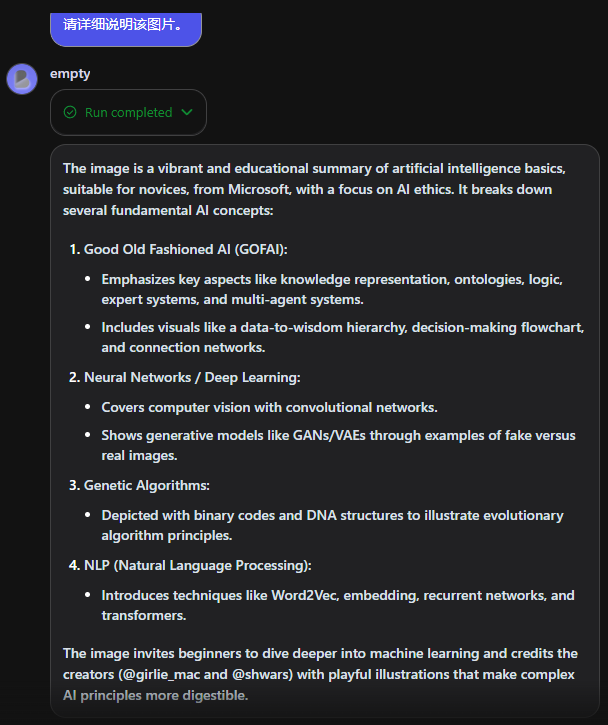
ChatGPT-4 Turbo 128k

Gemini 1.5 pro
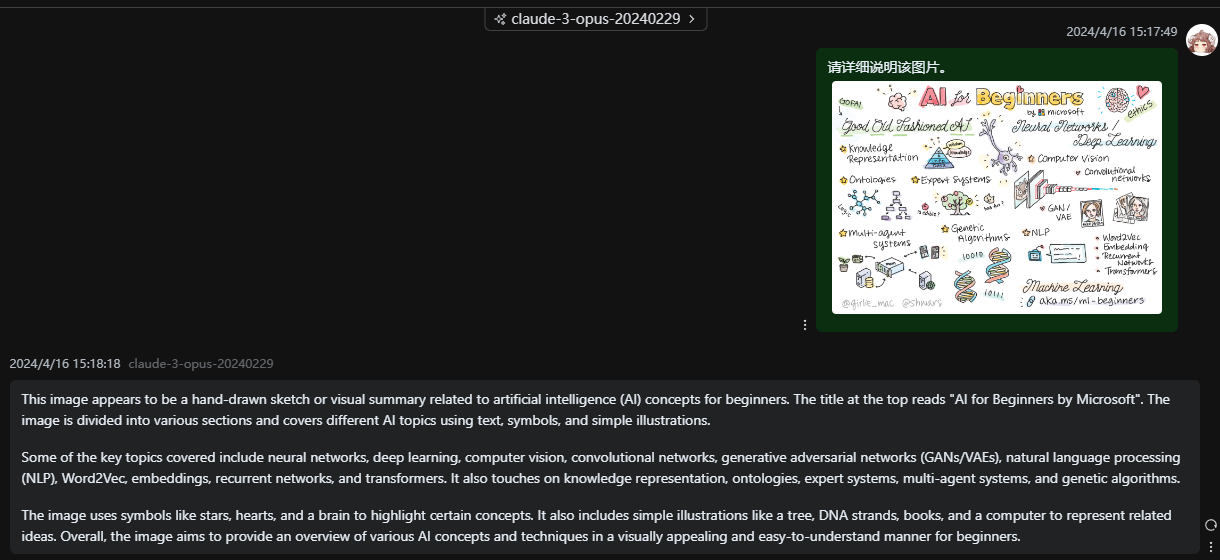
Claude 3 – Opus
Mini-Gemini的识别结果完全正确,毫不逊色ChatGPT-4 和Gemini 1.5 pro,而 Claude3-Opus 这次偷懒识别结果不完全。
高清图像理解与推理
以往的多模态模型多局限于低分辨率图像的处理,而Mini-Gemini 则打破了这一局限,能够解析高清图像,并进行相应的推理。
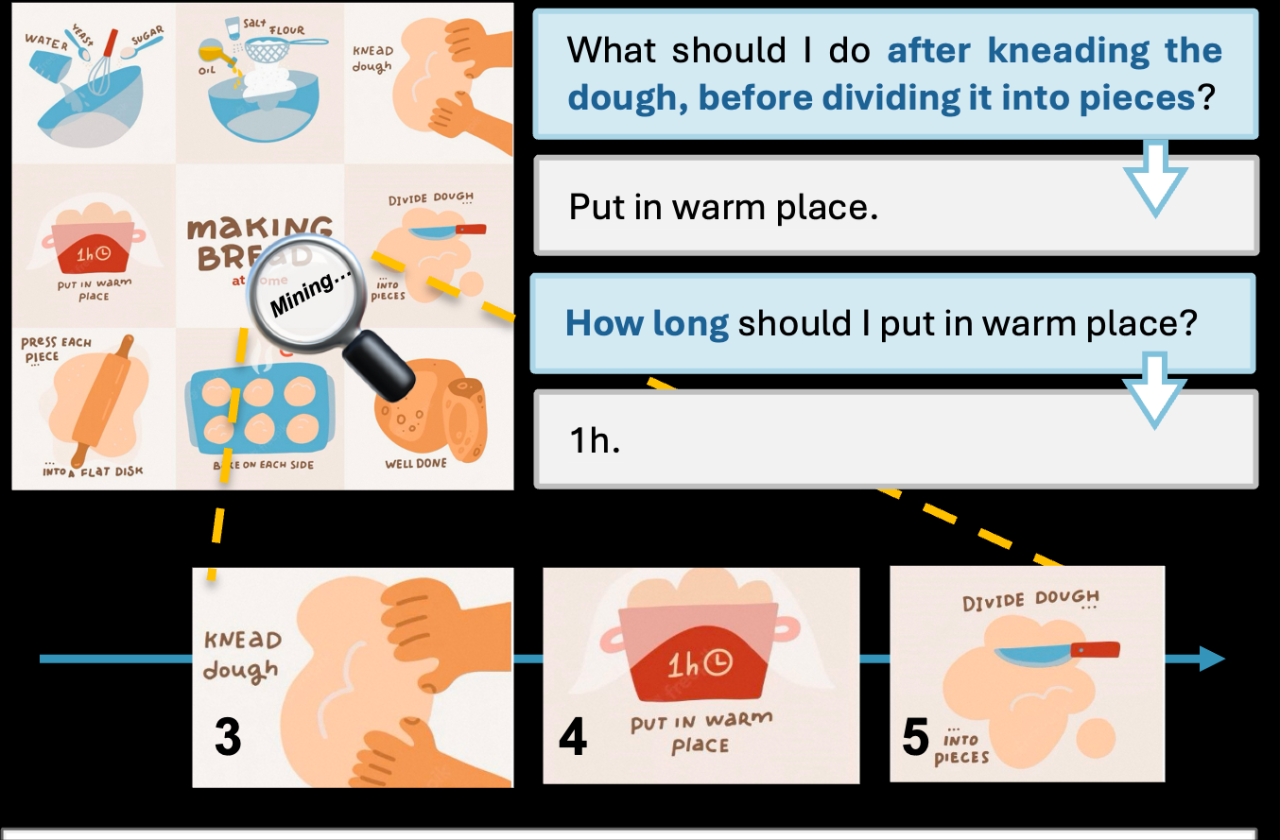
可以从识别图片中一个微小部分的文字

面对复杂的烘焙步骤,Mini-Gemini 可以轻松看懂面包九宫格教程,并像一位经验丰富的烘焙师一样,对每一个步骤进行详细的讲解,帮助用户轻松掌握烘焙技巧。
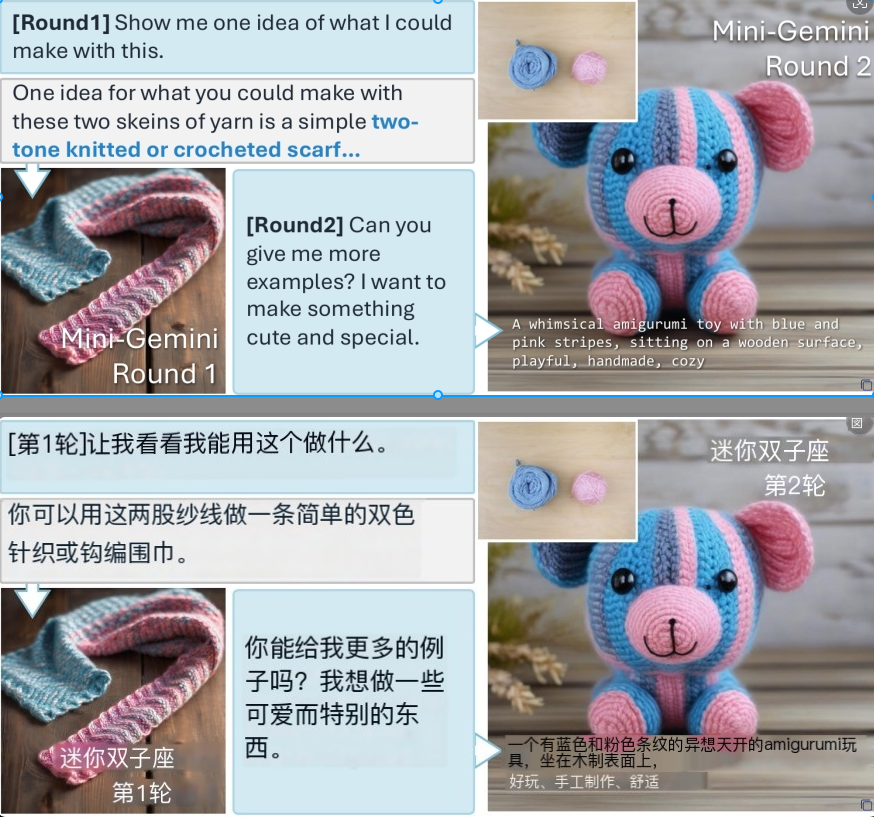
想要进行艺术创作却缺乏灵感?Mini-Gemini 可以成为你创意的伙伴,例如,只需提供两个简单的毛线团,它就能推理并生成毛线小熊的图片,激发你的创作灵感。
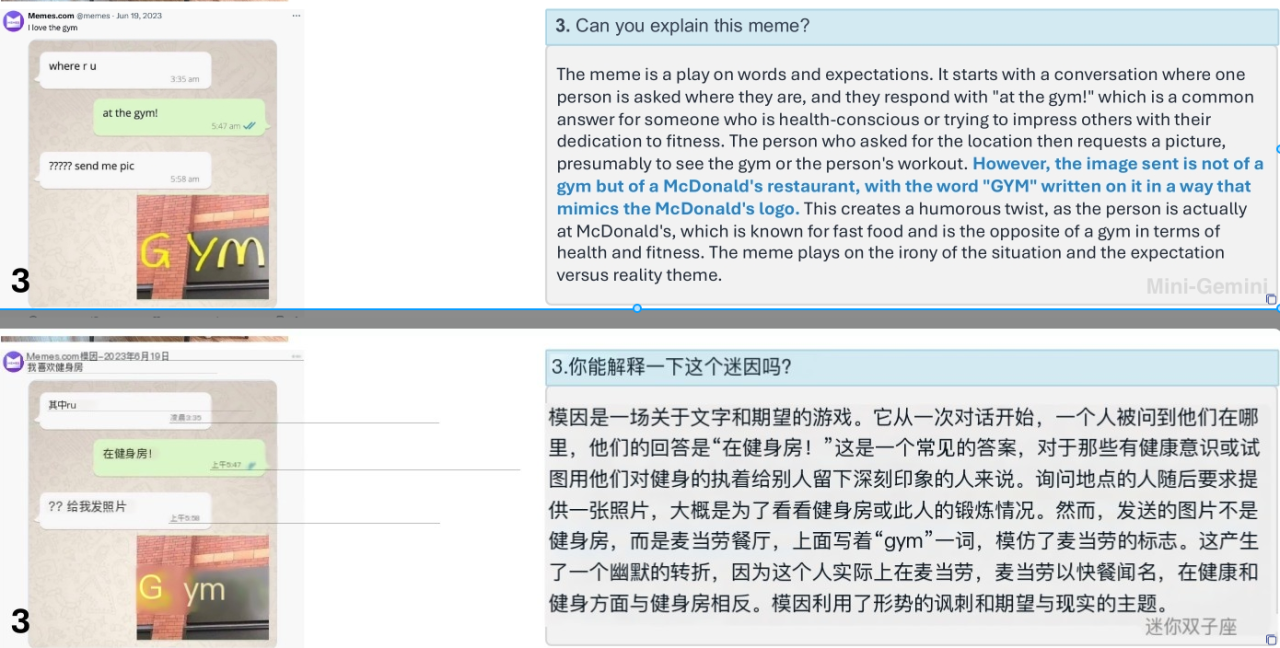
玩梗大师: 面对网络上层出不穷的梗图,Mini-Gemini 可以轻松理解其背后的幽默,并进行准确的解释。例如,一张将麦当劳标志P成健身房(GYM)的表情包,Mini-Gemini 就能准确解读其讽刺的含义。
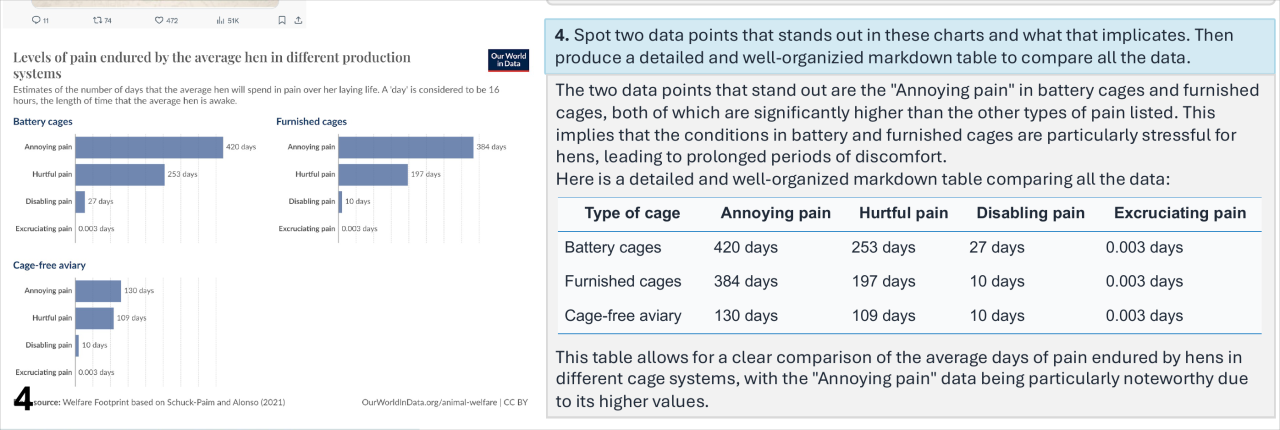
数据分析师: 面对复杂的数据图表,Mini-Gemini 可以化身专业的数据分析师,快速理解图表内容,并用简洁易懂的语言进行归纳总结。
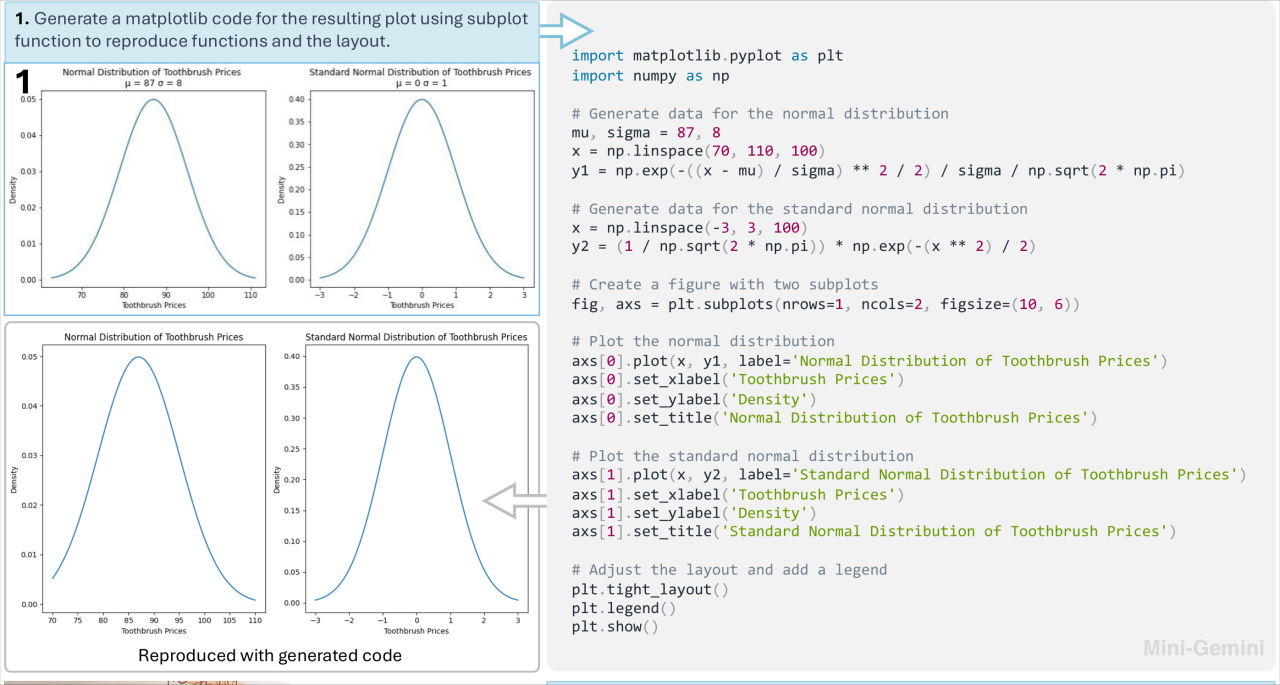
代码助手: Mini-Gemini 能够理解数学函数曲线图,并用代码进行复现,从而节省程序员宝贵的时间和精力。
图像生成
Mini-Gemini不仅具有出色的图像理解和推理能力,还能根据推理结果生成图像。它就像 ChatGPT 和 DALL-E 3 的结合,能够理解图像中的信息,并根据指令进行推理和生成图像。
给它一幅图,它能理解并生成类似的图像。
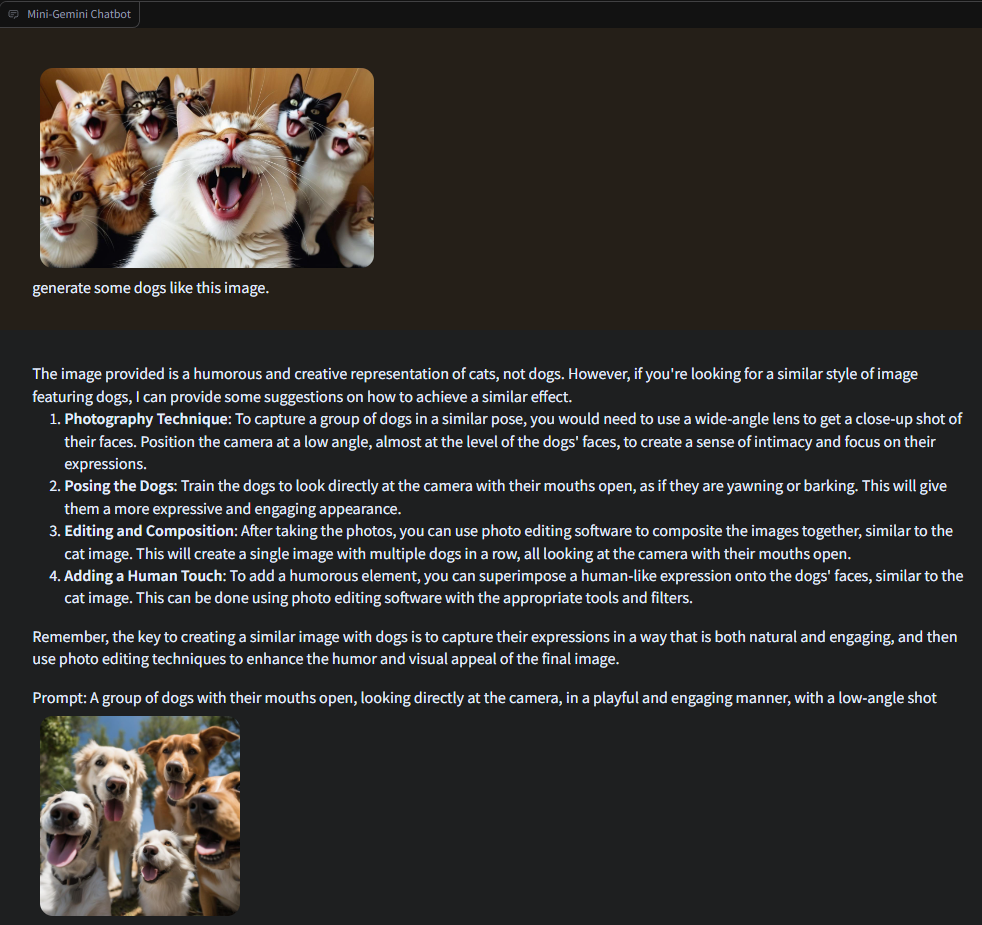
直接给它命令,它先推理出prompt后,再生成对应的图像。
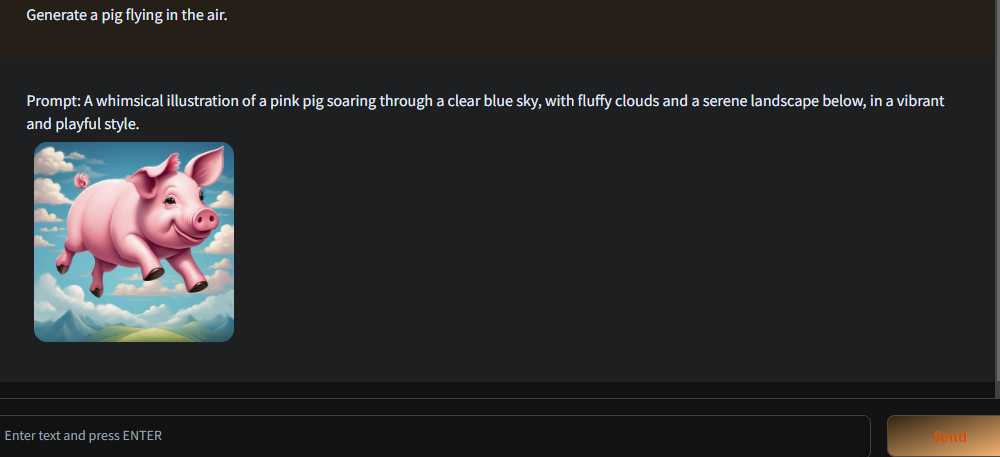
技术细节
Mini-Gemini 的强大能力,源于其独特的技术设计:
双编码器机制: 为了高效处理高清图像,Mini-Gemini 采用了双编码器机制。它使用 ViT 作为低分辨率的 Query,并使用卷积网络(ConvNet)将高分辨率的图像编码成 Key 和 Value。通过 Transformer 中常用的 Attention 机制,Mini-Gemini 能够挖掘每个低分辨率 Query 对应的高分辨率区域,从而在保持最终视觉 Token 数目不变的情况下,提升对高清图像的响应,保证了在大语言模型(LLM)中对于高清图像的高效编码。
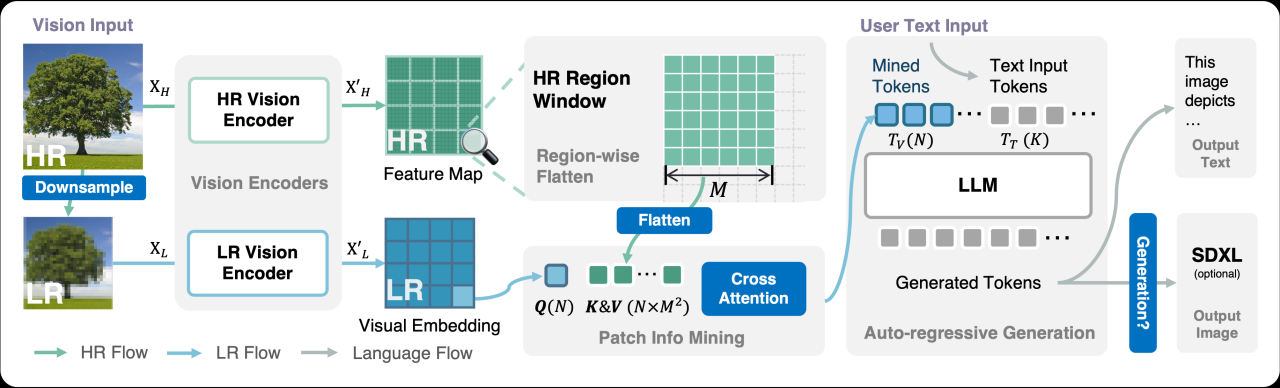
高质量数据: 数据是 AI 模型的“燃料”,Mini-Gemini 采用了更高质量的训练数据,并加入了与生成模型结合的文本数据进行训练。这使得 Mini-Gemini 在仅使用 2-3M 数据的情况下,就能实现对图像理解、推理和生成的统一流程,并在各种 Zero-shot 榜单上取得优异成绩。
生成模型拓展: 为了实现图像生成功能,Mini-Gemini 借助了 SDXL 生成模型。LLM 在进行推理后,会生成相应的文本信息,并将其与 SDXL 模型连接,从而实现图像的生成,类似于 DALL-E 3 的流程。而且Mini-Gemini还可以插拔其他的绘画模型。