12 月 6 日晚,谷歌 DeepMind 推出了其“迄今为止最强大、最通用的模型”Gemini。一位观察家表示,Gemini 是一台“万能机器”,在各种性能上都是同类最佳的。谷歌及其母公司 Alphabet 的首席执行官桑达尔 – 皮查伊(Sundar Pichai)在接受采访时也表示:“这对我们来说是向前迈出的一大步。”
是的,对于谷歌而言,相比此前饱受诟病的 Bard,Gemini 是进步,但对整个 AI 领域来说未必是一个巨大的飞跃。
作为对 OpenAI GPT-4 的回应,谷歌 DeepMind 声称,Gemini 在 32 项标准性能指标中,有 30 项指标都优于 GPT-4。然而,它们之间的差距其实是微乎其微的。谷歌 DeepMind 所做的,其实只是将人工智能目前最好的能力整合到一个强大的软件包中。从演示来看,它在很多方面都做得很好,但很少有我们以前没见过的东西。
Gemini 可能是一个迹象,表明我们已经达到了人工智能炒作的顶峰。至少现在是这样。
华盛顿大学专门研究在线搜索的教授 Chirag Shah 把这次发布比作苹果公司近年推出的新款 iPhone。他说:“也许我们现在只是上升到了一个不同的阈值,在这个阈值上,这并没有给我们留下那么深刻的印象,因为我们已经看过太多(类似的产品和功能了)。”
与 GPT-4 一样,Gemini 也是多模态的,这意味着它经过训练可以处理多种输入:文本、图像、音频。它可以将这些不同的格式结合起来,回答从家务到大学数学到经济学等各种问题。
在昨天为记者进行的演示中,谷歌展示了 Gemini 的性能,它可以截取现有图表的截图,分析数百页的研究报告和新数据,然后根据新信息更新图表。在另一演示中,Gemini 显示了在平底锅中烹饪蛋饼的图片,并询问(使用语音而非文字)蛋饼是否已经熟透。Gemini 也能准确地答上来:“还没熟,因为蛋液还是流动的。”
目前,Gemini 还未完全上线。今天推出的版本是谷歌基于文本的搜索聊天机器人 Bard 的后端。Gemini 的全面发布将在未来几个月内分期进行。经过 Gemini 强化的新 Bard 最初将在 170 多个国家(不包括欧盟和英国)提供英语版本。负责 Bard 的谷歌副总裁 Sissie Hsiao 说,这是为了让公司与当地监管机构“接触”。
具体而言,Gemini 有三种规格:Ultra、Pro 和 Nano。其中,Ultra 是全功率版本;Pro 和 Nano 则是为计算资源有限的应用程序量身定制的。Nano 则专为在谷歌新款 Pixel 手机等设备上运行而设计。开发人员和企业将从 12 月 13 日开始访问 Gemini Pro。Gemini Ultra 是功能最强大的规格,将在“明年初经过”广泛的信任和安全检查“后推出。
“我认为大模型已经到了 Gemini 时代,”皮查伊表示。“这就是谷歌 DeepMind 在人工智能领域的构建和进步方式。它永远代表着我们在人工智能技术方面取得进展的前沿。”
更大、更好、更快、更强?
OpenAI 最强大的模型 GPT-4 被视为业界的黄金标准。虽然谷歌夸口说 Gemini 比 OpenAI 之前的模型 GPT 3.5 性能更强,但公司高管回避了关于该模型比 GPT-4 强多少的问题。
在与同类大模型相比时,谷歌特别强调了一个名为 MMLU(大规模多任务语言理解)的基准。这是一套测试,旨在衡量模型在涉及文本和图像的任务中的表现,包括阅读理解、大学数学以及物理、经济和社会科学方面的多项选择测验。皮查伊说,在纯文本问题上,Gemni 的得分率为 90%,人类专家的得分率约为 89%,而 GPT-4 在这类问题上的得分率为 86%。在多模态问题上,Gemini 的得分率为 59%,而 GPT-4 的得分率为 57%。皮查伊说:“这是第一个跨过这个门槛的模型。”
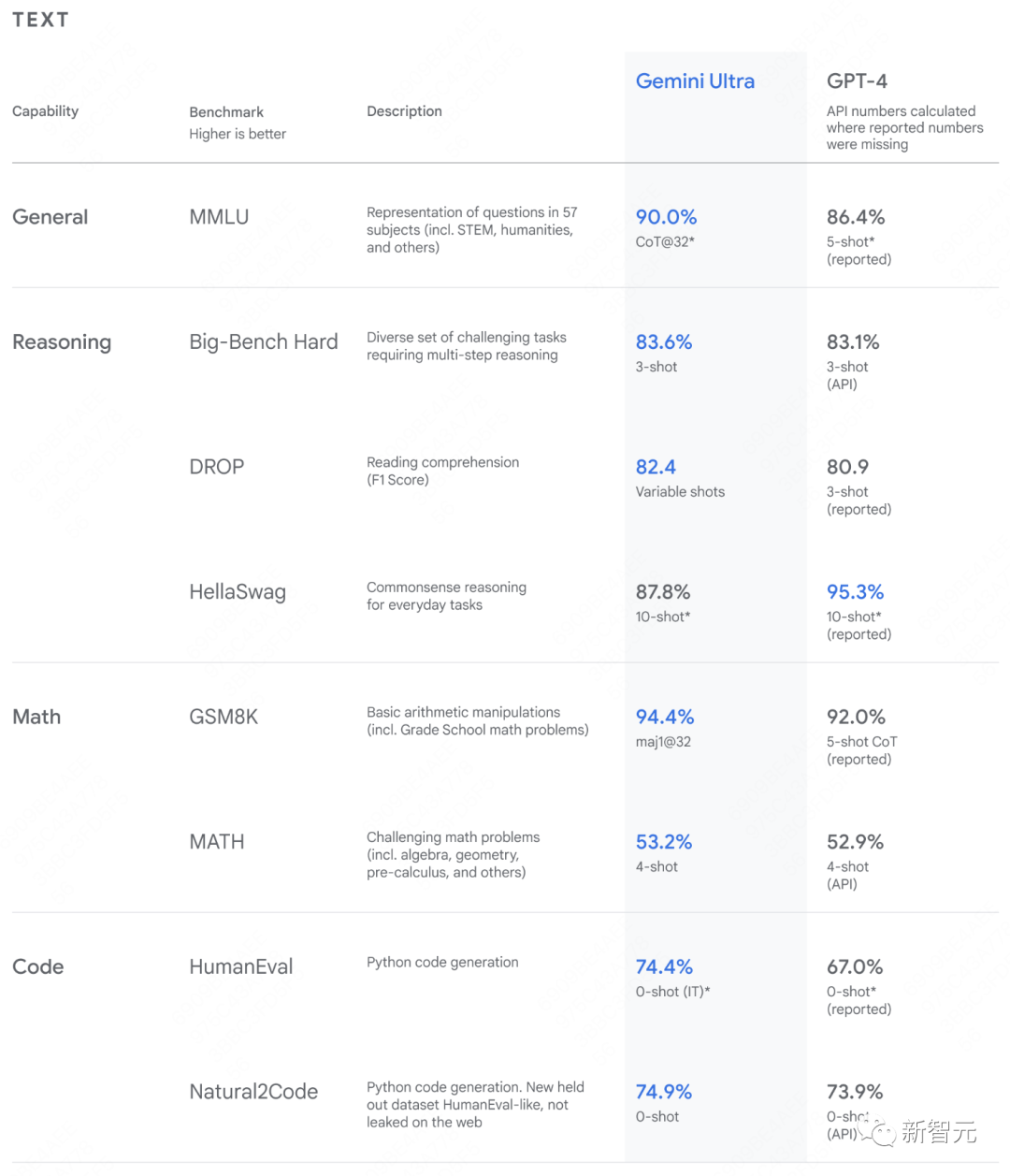
的确,在数据上,Gemini 的成绩好于 GPT-4,但真的不多。
新墨西哥州圣达菲研究所(Santa Fe Institute)的人工智能研究员 Melanie Mitchell 就表示,“很明显,Gemini 是一个非常复杂的人工智能系统。”但“在我看来,Gemini 的能力实际上并没有明显超过 GPT-4,”她补充说。
此外,斯坦福大学基础模型研究中心主任 Percy Liang 也谈到,虽然该模型有很好的基准分数,但由于我们不知道训练数据的内容,因此很难解释这些数据。
Mitchell 还指出,Gemini 在不同基准上的表现也没那么稳定,语言和代码方面的表现要比在图像和视频方面好得多。她说:“多模态基础模型要想在许多任务中发挥普遍而强大的作用,还有很长的路要走。”
据悉,谷歌 DeepMind 利用人类测试者的反馈对 Gemini 进行了训练,使其能地反映事实,在被要求时给出归因,并在面对无法回答的问题时回避而不是胡言乱语。谷歌称,这可以减轻幻觉问题。但是,如果不对基础技术进行彻底改革,大型语言模型将继续胡编乱造。
专家表示,目前还不清楚谷歌用来衡量 Gemini 性能的基准是否能提供那么多的洞察力,而且在不透明的情况下,也很难核实谷歌的说法。
华盛顿大学计算语言学教授 Emily Bender 说:“谷歌宣传 Gemini 是一台万能机器 — 一个可用于多种不同用途的通用模型。”但是,该公司正在使用狭隘的基准来评估它期望用于这些不同用途的模型。“这意味着它实际上无法得到彻底评估,”她说。
Shah 表示,最终,对于普通用户来说,与竞争模型相比的进步可能不会带来太大的影响。“这更多的是便利性、品牌认知度和现有集成,而不是人们真正认为‘哦,这个更好’,”他说。
漫长而缓慢的积累
Gemini 的诞生由来已久。2023 年 4 月,谷歌宣布将其人工智能研究部门 Google Brain 与 Alphabet 位于伦敦的人工智能研究实验室 DeepMind 合并。因此,谷歌花了近一年的时间来开发其应对 OpenAI 最先进的大型语言模型 GPT-4 的答案。
谷歌一直承受着巨大的压力,它必须向投资者展示自己在人工智能领域能够与竞争对手匹敌,甚至超越对手。虽然谷歌多年来一直在开发和使用功能强大的人工智能模型,但由于担心声誉受损和安全问题,它一直对推出公众可以使用的工具犹豫不决。
今年 4 月,杰弗里 – 辛顿(Geoffrey Hinton)在离开谷歌时表示:“谷歌在向公众发布这些东西方面一直非常谨慎。”“可能发生的坏事太多了,谷歌不想毁了自己的声誉。”面对似乎不可信或无法销售的技术,谷歌采取了稳妥的做法 — 直到更大的风险变成了错失良机。
谷歌已经深刻认识到,推出有缺陷的产品可能会适得其反。今年 2 月,谷歌推出了 ChatGPT 的竞对巴德(Bard),但科学家们很快就发现该公司自己为聊天机器人所做的广告中存在事实错误,这一事件也导致谷歌市值蒸发了 1000 亿美元。
今年 5 月,谷歌宣布在从电子邮件到生产力软件的大部分产品中推出生成式人工智能。但结果并未给大伙儿留下深刻印象:例如,聊天机器人提到了并不存在的电子邮件。
这是大型语言模型一贯存在的问题。生成式人工智能系统虽然擅长生成听起来像是人类写的文字,但经常会胡编乱造。而且它们还容易被黑客攻击,并且充满偏见。
谷歌既没有解决这些问题,也没有解决幻觉问题。对于后一个问题,谷歌的解决方案是让人们使用谷歌搜索来重复检查聊天机器人的答案,但这依赖于在线搜索结果本身的准确性。
Gemini 可能是这波生成式人工智能浪潮的顶峰。但建立在大型语言模型基础上的人工智能下一步将走向何方,目前还不清楚。一些研究人员认为,这可能只是一个平台期,而非下一个高峰的开端。
然而,对于未来,皮查伊并不悲观。他说:“展望未来,我们确实看到了很大的发展空间。”“我认为多模态将大有作为。当我们教会这些模型更多地进行推理时,将会有越来越大的突破。更深层次的突破还在后面。”“从整体上看,我真的觉得我们正处于起步阶段。”