Google Gemini是谷歌最新发布的强大人工智能模型,不仅可以理解文本,还能处理图像、视频和音频。作为一种多模态模型,Gemini被描述为能够在数学、物理等领域完成复杂任务,同时能够理解并生成各种编程语言中的高质量代码。

Gemini由Google和其母公司Alphabet共同创建,并作为该公司迄今为止最先进的AI模型发布。Google DeepMind在Gemini的开发中也做出了重要贡献。
Gemini有不同版本吗?
谷歌将Gemini描述为一种灵活的模型,可以在从谷歌数据中心到移动设备的各种平台上运行。为了实现这种可扩展性,Gemini被分为三个版本:Gemini Nano、Gemini Pro和Gemini Ultra。
- Gemini Nano: 设计用于在智能手机上运行,特别是Google Pixel8。它专为在设备上执行需要高效AI处理的任务而构建,无需连接到外部服务器,如在聊天应用中建议回复或总结文本。
- Gemini Pro: 在谷歌的数据中心运行,旨在为公司最新版本的AI聊天机器人Bard提供动力。它能够快速响应并理解复杂的查询。
- Gemini Ultra:尽管目前还没有广泛使用,但谷歌将Gemini Ultra描述为其最强大的模型,超过了“在大型语言模型(LLM)研究和开发中使用的32个广泛使用的学术基准中的30个”的当前最先进结果。它专为高度复杂的任务设计,并计划在完成当前测试阶段后发布。
Gemini怎么使用?
Gemini现在可以在Google产品中的Nano和Pro版本上使用,如Pixel8手机和Bard聊天机器人。谷歌计划随着时间的推移将Gemini逐步整合到其搜索、广告、Chrome和其他服务中。
开发人员和企业客户将能够通过Google的AI Studio和Google Cloud Vertex AI中的Gemini API在12月13日开始访问Gemini Pro。Android开发人员将通过AICore在早期预览阶段访问Gemini Nano。
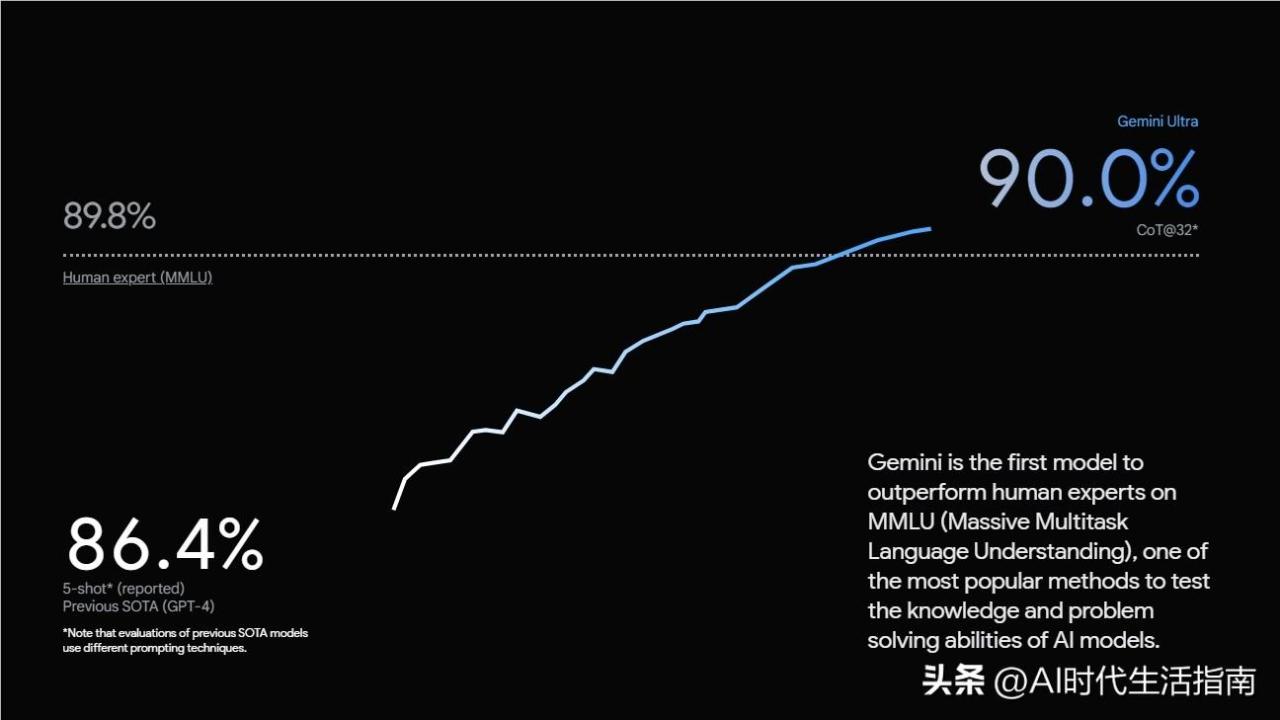
Gemini与GPT-4等其他AI模型有何不同?
谷歌的新Gemini模型似乎是迄今为止最大、最先进的AI模型之一,尽管Ultra模型的发布将最终确定这一点。与当前驱动AI聊天机器人的其他流行模型相比,Gemini因其本地多模态特性而脱颖而出,而其他模型如GPT-4则依赖于插件和集成才能真正实现多模态。
与主要基于文本的模型GPT-4相比,Gemini可以轻松进行本地多模态任务。虽然GPT-4在语言相关任务方面表现出色,如内容创作和复杂文本分析,但它需要依赖OpenAI的插件进行图像分析和访问网络,并依赖DALL-E3和Whisper生成图像和处理音频。
Gemini还比当前可用的其他模型更加产品化。它要么已经集成到公司的生态系统中,要么计划集成,因为它同时为Bard和Pixel8设备提供动力。其他模型,如GPT-4和Meta的Llama,更加服务导向,可用于各种第三方开发人员的应用程序、工具和服务。
Google Gemini的推出标志着谷歌在人工智能领域的进一步创新。其多模态特性使其在处理不同类型的信息时更加灵活,为用户提供了更广泛的应用场景。随着Gemini的逐步整合到谷歌的生态系统中,我们可以期待看到更多令人惊叹的应用和服务。