就在这周的前几天,OpenAI和Google都相继发布了新的大模型产品。尽管真正的具身智能还有很长的路,但大家都在借助新的AI想定义新的人机交互标准,在多模态交互上,迈出关键一步。

这是我们首次在易用性方面取得重大突破,意义非凡!因为这揭示了我们与机器之间未来的互动方式。
——Mira Murati OpenAI首席技术官
GPT-4o的发布,无疑是昨日AI圈一大焦点。很多文章都做了详细介绍和功能解析,总结下来有3个核心优势:
使用门槛更低:免费开放、API价格减半、Mac版工具
使用体验更好:速度翻倍、跨模态推理、自然对话
使用场景更丰富:情绪感知、实时语音、视觉增强
其中最能引发遐想的,我觉得是“实时理解世界”的能力,包括对物理现实的理解,和人类情绪的理解。

无独有偶,就在5月15日凌晨,谷歌在Google I/O开发者大会展示了名为“Gemini Live”的新体验:
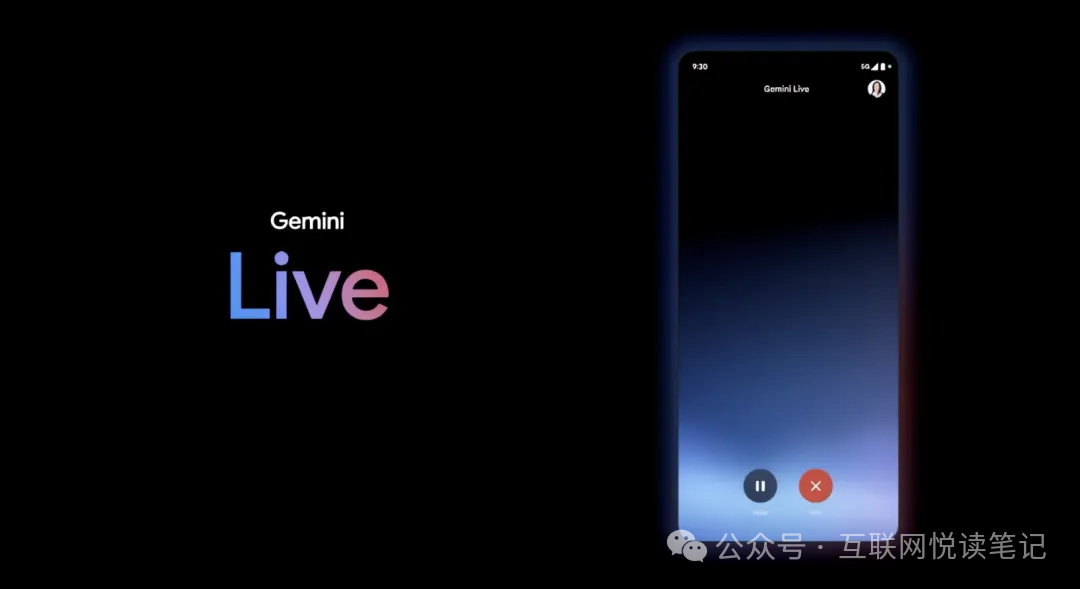
和GPT-4o一样,Gemini Live可以通过手机摄像头拍摄的照片或视频,查看用户的周围环境,并对其做出反应。作为人类的代理,它可以看到和听到我们所做的事,更好地了解我们所处的环境,并在对话中快速做出反应,从而让交互更自然。
这项能力的发布,很明显都在指向一个关键词:具身智能。
具身智能强调“感知—行动回路”,并呈现出三个特点:
一定是多模态的,能像人一样通过视觉、听觉、触觉等感官,以及语言、运动、交互等行为,完成一系列智能任务。
能根据环境的交互积累经验,基于不同数据构建不同模型,产生不同的智能,在完成任务上更智能;
机器人或智能体有自主性,和人类的学习和认知过程一致。
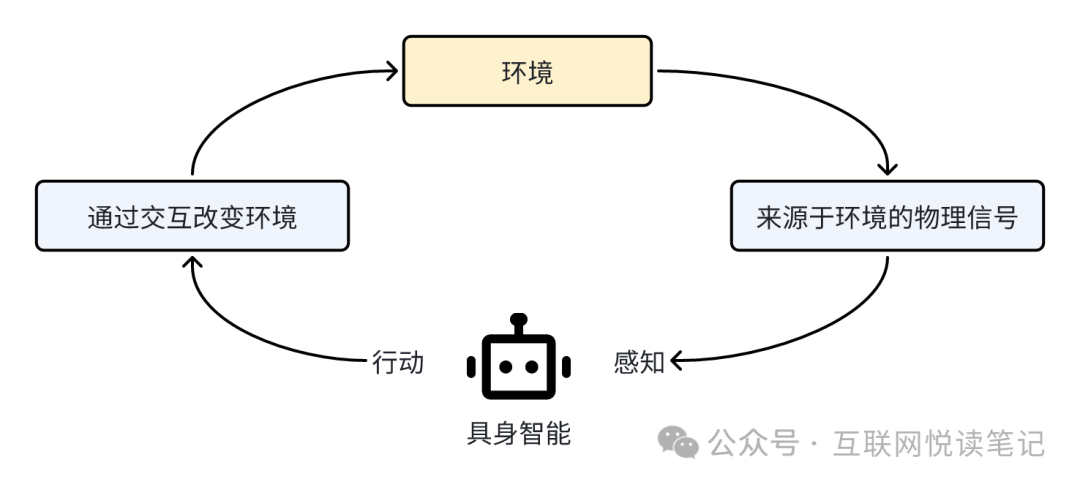
尽管距离真正的具身智能还有很长的路要走,但我看到了在多模态交互上,人类迈出了关键一步。
我觉得无论是OpenAI还是谷歌,都在借助新的AI技术,为我们制定了新的大模型产品的人机交互标准。
一、大模型产品的人机交互标准是什么?
说起大模型产品的交互方式,通常第一反应都是CUI(Conversational User Interface 对话式用户交互界面),或者叫LUI(Language User Interface,语言交互界面)。甚至很多人一度认为,这就是AI产品最终的交互方式了。
然而真是这样么?回归到交互的本质,无论是图形界面,还是对话界面,目的都是要更精准地解读用户的输入意图,达成更匹配的输出。
表面上看,似乎用对话方式,用户可以更自由、灵活地表达需求,而不用局限在产品经理预设的界面上去完成任务。然而,回归到交互设计原则上看,到底什么样的交互,是真正对用户友好的?
著名的美国认知心理学家、用户体验设计大师唐·诺曼(Don Norman),曾提过一个好产品的交互设计六项基本原则,分别是:
示能(Affordance)
指一个物理对象本身就有的、特定的交互方式,不需要解释,它直接就可以被感知到。比如一把椅子,不管它怎么设计,一定会有一个平面可以坐人。这里面的“平面”,就是一种示能。一出现平面,人们就会天然地认为,这个地方是可以坐的。
意符(Signifiers)
意符是一种提示,告诉用户可以采取什么行为。比如我们经常看到,有些商场的大门上,会写上“推”或者“拉”的提示,这个推和拉就是一种意符。
约束(Constraint)
约束限定了一系列可能的操作。在设计中有效使用约束因素,就可以让用户在任何未知环境下都能找到合适的操作方法。比如拼乐高积木、使用电源插座。
映射(Mapping)
映射表示两组事物要素之间的关系,是可以直观反映在物理位置上的。比如办公室的顶灯和对应的开关,它们之间的排布是一一对应的,你就可以知道按哪个按钮开关哪排灯。
反馈(Feedback)
好设计一定要有即时反馈,稍有延迟便会令人不安。生活中我们经常会碰到有人在电梯前反复按楼层键,就是因为缺少及时反馈。反馈需要精心策划,以一种不显著的方式确认所有操作。
概念模型(Conceptual Models)
指高度简化的说明,告诉用户产品是如何工作的。比如电脑中的文件和文件夹就是一套概念模型,实际上硬盘上并不存在文件夹,但这比复杂的计算机指令更能让用户理解计算机的操作。