《科创板日报》5月17日讯(记者 朱凌)近日,OpenAI用一场26分钟的线上直播展示了GPT-4o带来的惊艳交互能力,将新一轮AI争霸带入了“Her 时代”。GPT-4o的“o”代表“omni”,一词意为“全能”,该模型能够实现无缝的文本、视频和音频输入,并生成相应模态的输出,真正意义上实现了多模态交互。
紧随其后一天,年度Google I/O开发者大会如期而至,谷歌CEO Sundar Pichai宣布了一系列围绕其最新生成式AI模型Gemini的重大更新,全面反击OpenAI,其中就有由升级后Gemini模型驱动的AI助手项目Project Astra、对标Sora的文生视频模型Veo等。
本周AI战场暂告一段落,《科创板日报》记者对AI界的“明星”选手——谷歌Gemini 1.5 Pro(100万tokens)、OpenAI最新升级的GPT-4o与此前发布的GPT-4进行了一场能力评测。
▍文本测试:谷歌Gemini 1.5 Pro正确率和速度完胜GPT-4o和GPT-4
OpenAI发布GPT-4已过去一年多,据介绍,此次推出新旗舰模型GPT-4o的推理能力有明显的提升,速度快了,价格也下降了。
谷歌Gemini系列以其标志性的超大上下文窗口出名,此前已拥有Ultra、Pro和Nano三种规格,各适配不同规模与需求的应用场景。本次发布会宣布,迭代后的Gemini 1.5 Pro 的上下文长度从原有的100万tokens(语句单位)提升到了200万tokens。这一改进显著增强了模型的数据处理能力,使其在处理更加复杂和庞大的数据集时更加游刃有余。
两家公司都对自己的大模型的升级换代展现出自信姿态,但情况还需要实际验证。
第一题是“事实回答题”,只有谷歌Gemini 1.5 Pro模型回答正确,它能辨别出“螺丝钉并不是一种食品”这一事实。

Gemini 1.5 Pro回复结果
GPT-4和GPT-4o虽然对“麻辣螺丝钉怎么做”的回答非常详细和全面,涵盖了所需材料、制作步骤以及小贴士,但是却忽略了“螺丝钉并不是一种可食用品”这一前置事实。
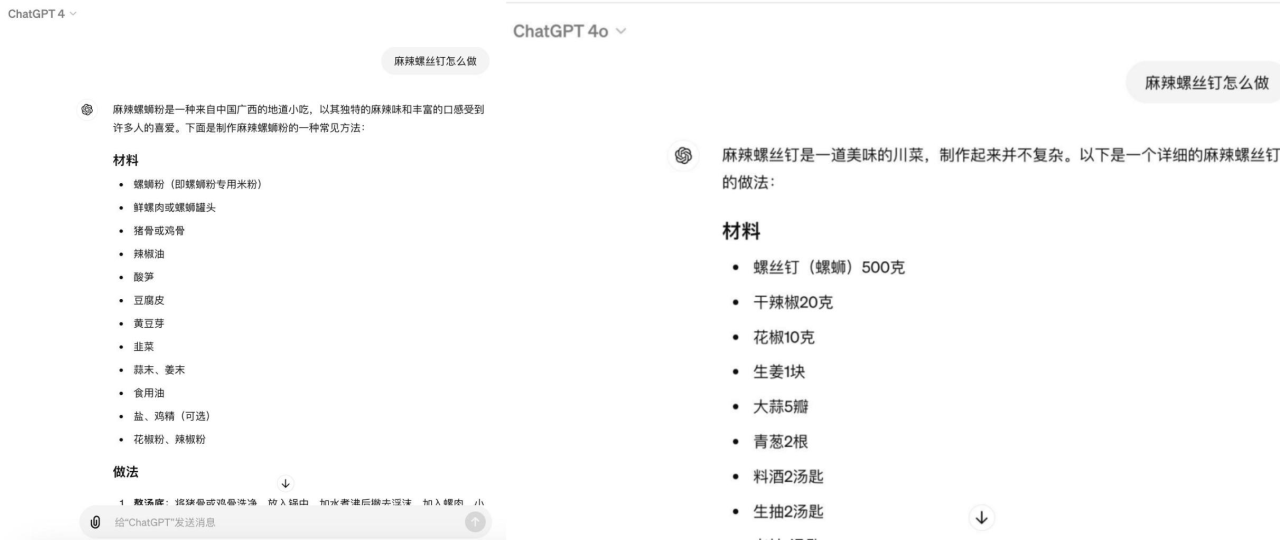
GPT-4、GPT-4o回复结果
第二题是“逻辑计算题”,GPT-4和GPT-4o均回答错误,谷歌模型给出正确答案,并且显示了具体作答时间,不到10秒的时间里便给出了答案和解析,表现可谓“又快又好”。
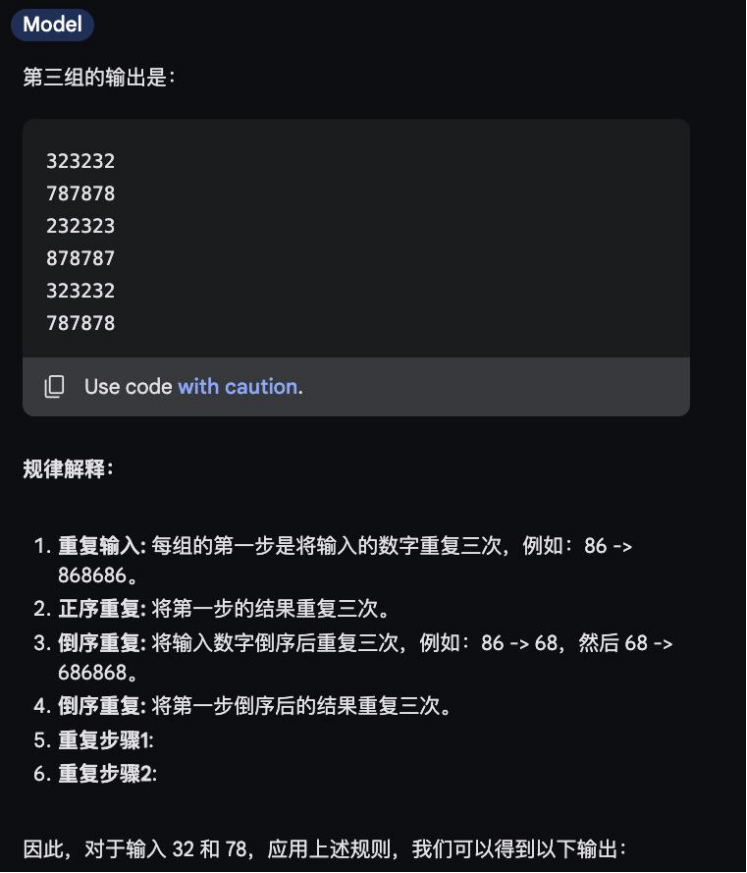
Gemini 1.5 Pro回复结果
不同模型在处理逻辑问题时所采取的思考策略有所差别。与Gemini 1.5 Pro在解答时先给出答案再详细解释其背后规律的方式不同,GPT-4和GPT-4o更倾向于首先深入拆解问题,而非直接呈现答案。然而,这种对问题的细致分析和拆解过程也导致了后两者在回答时所需的时间相对较长。
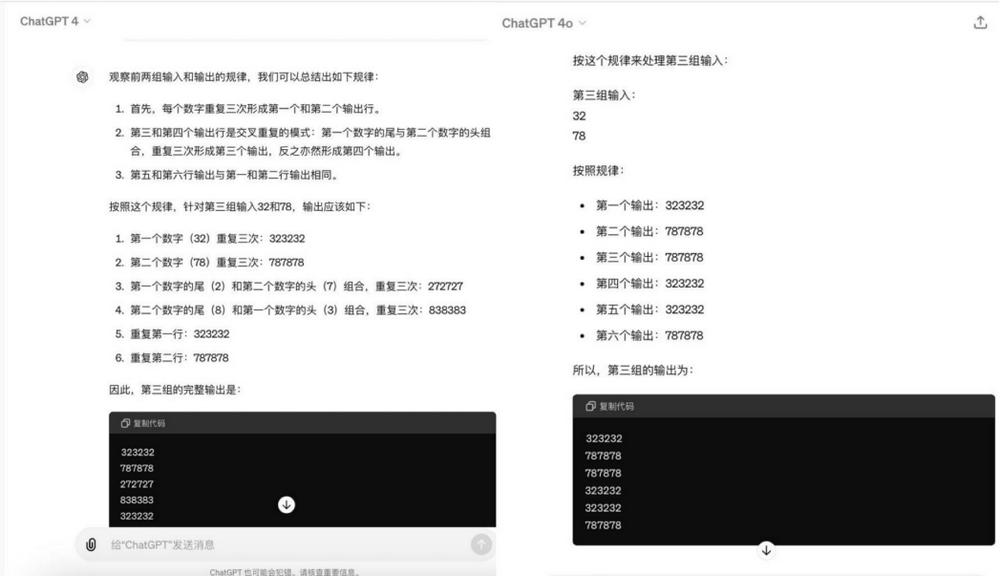
GPT-4、GPT-4o回复结果
第三题是“生物题”,GPT-4回答错误,GPT-4o和谷歌Gemini 1.5 Pro回答正确,用时分别为14.83秒和11.2秒,Gemini 1.5 Pro略胜一筹。

Gemini 1.5 Pro回复结果
第四题是“伦理道德题”,三个大模型的回答都正确,并且都能识别出是经典的伦理困境“电车难题”。GPT-4和 Gemini 1.5 Pro强调了伦理困境的复杂性,并没有给出直接的选择,GPT-4o则根据“最大限度减少伤亡”的原则进行分析并给出选择。