在 Google I/O 大会上,Google 发布了升级后的 Gemini 1.5 Pro,并推出了 Gemini 1.5 Flash。近期,Google 发布了更新后的 Gemini 1.5 技术报告。
报告链接
https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
报告亮点
Google Logan Kilpatrick 指出报告亮点:
Gemini 1.5 Pro(五月版)现已成为 Google 最强大的模型(超越 1.0 Ultra)
Gemini 1.5 型号在跨模态的长上下文检索任务中实现了近乎完美的回忆
在长文档问答、长视频问答和长上下文自动语音识别(ASR)方面的表现有所提升
在下一个标记预测和长达至少 1000 万个标记的近乎完美检索(>99%)方面有了改进
报告很长,在此,我摘录了报告的部分内容,并做了简单分析。
Gemini 1.5 Pro 模型 2 月 VS 5 月
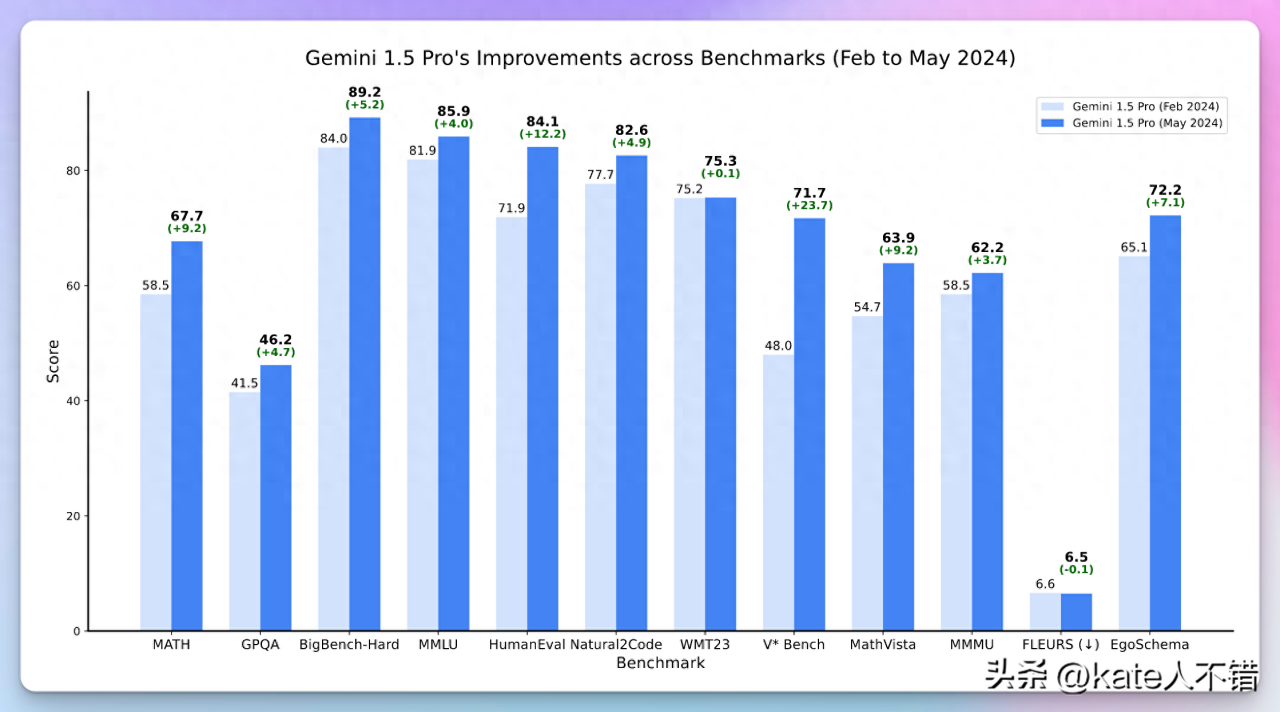
图 1:Gemini 1.5 Pro 模型在多个基准测试中的进步
图片显示了 Gemini 1.5 Pro 模型在多个基准测试中取得的显著进步,在几乎所有基准测试中,分数都有所提升,特别是在 HumanEval 和 V* Bench 上的提升尤为明显,分别提高了 12.2 和 23.7 分。这反映了模型在不同任务上的综合能力显著增强。
不同语言不同模型 API 效率对比
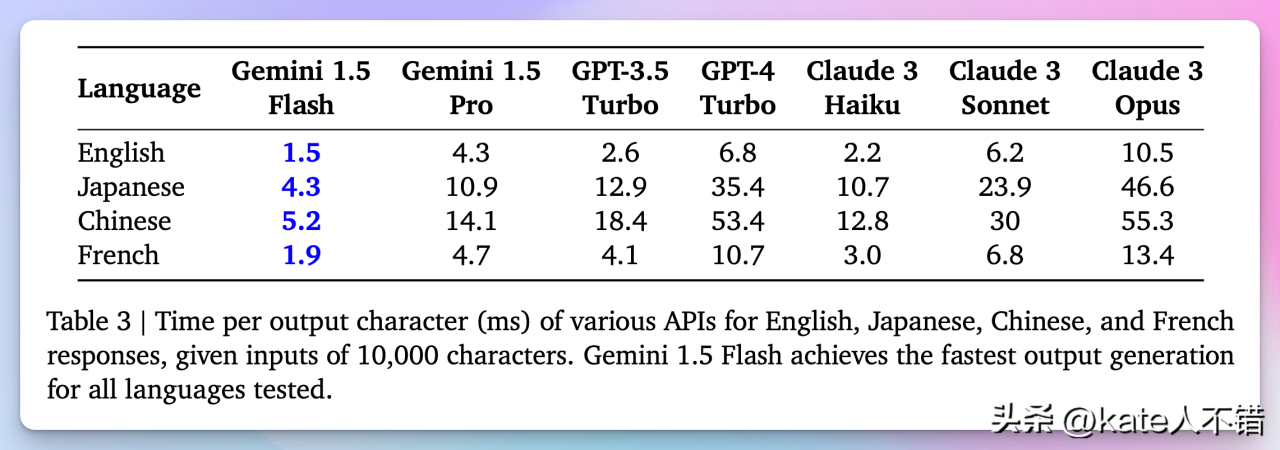
图 2:不同模型在多种语言中的输出生成速度对比
Gemini 1.5 Flash 在所有测试语言中都表现出最快的输出生成速度,表明其在高效性与低延迟方面具有优越性能。相比之下,其他模型(如 GPT-4 Turbo 和 Claude 3 系列)的延迟相对较高,尤其是在处理日语和中文时。
我之前提到 Claude 3 haiku 是性价比很高的模型,现在我认为 Gemini 1.5 Flash 可能更具性价比。
与 Claude 3 haiku 相比,Gemini 1.5 Flash 不仅支持音频和视频,还支持更长的上下文。
Claude 3 Haiku 的输入成本为每百万 tokens $0.25,输出成本为每百万 tokens $1.25。
而 Gemini 1.5 Flash 在 128k 上下文长度以下的价格为 $0.35 和 $0.53。此外,Gemini 1.5 Flash 的性能接近于 Gemini 1.5 Pro。
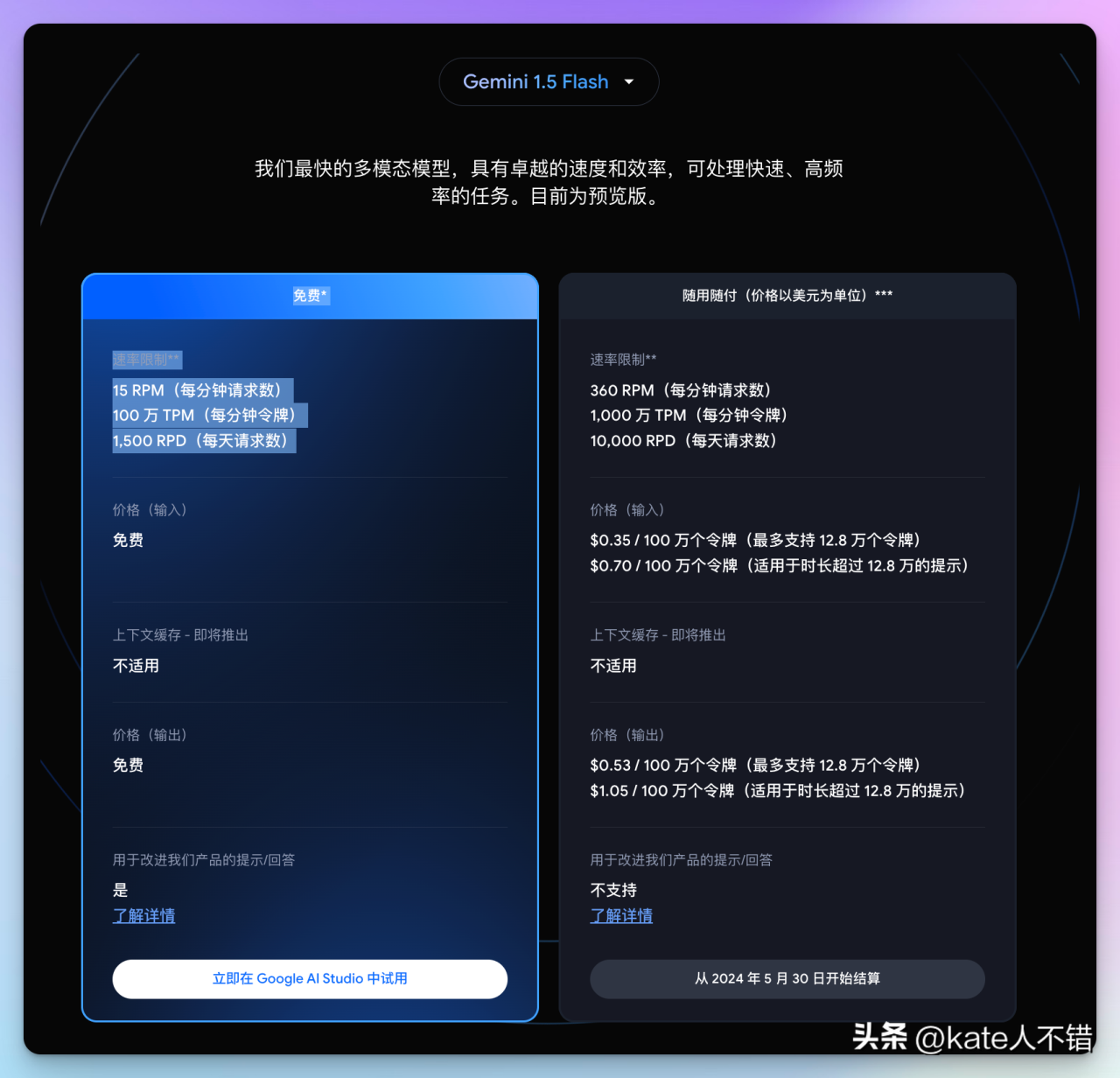
图 3:Gemini 1.5 Flash 价格
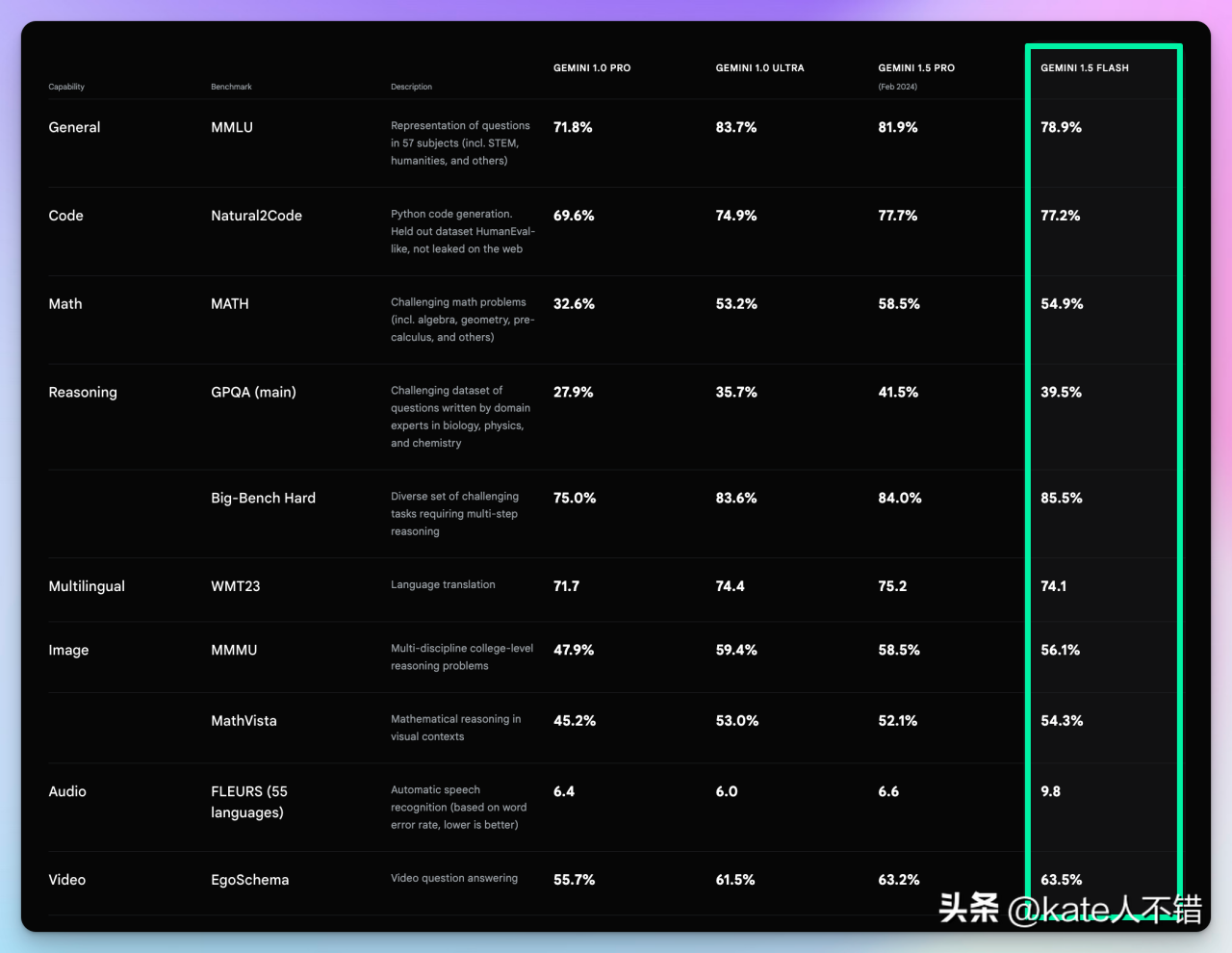
图 4:不同模型性能对比

图 5:Gemini 1.5 Pro 模型在处理大规模代码的表现
上下文长度达到 1M 对代码分析非常有用。这张图片展示了 Gemini 1.5 Pro 模型在处理大规模代码库时的能力。用户询问 JAX 代码库中自动微分的反向传播实现所在的文件。Gemini 1.5 Pro 在提供了整个代码库(746,152 个标记,116 个文件)的上下文后,准确地找到了实现文件
jax/_src/interpreters/ad.py,并提供了相关代码片段。图片展示了模型在处理长上下文和复杂代码检索任务中的强大能力,体现了其在帮助开发者查找特定代码实现和优化大型项目代码方面的实际应用价值。
根据我的使用经验,将整个代码库上传,然后让模型基于上传的内容找到特定目标代码,这种方法非常有效。
上下文长度长了,那输出准确性如何?
Gemini 1.5 Pro 技术报告对比了 GPT-4 在长文本处理上的表现。
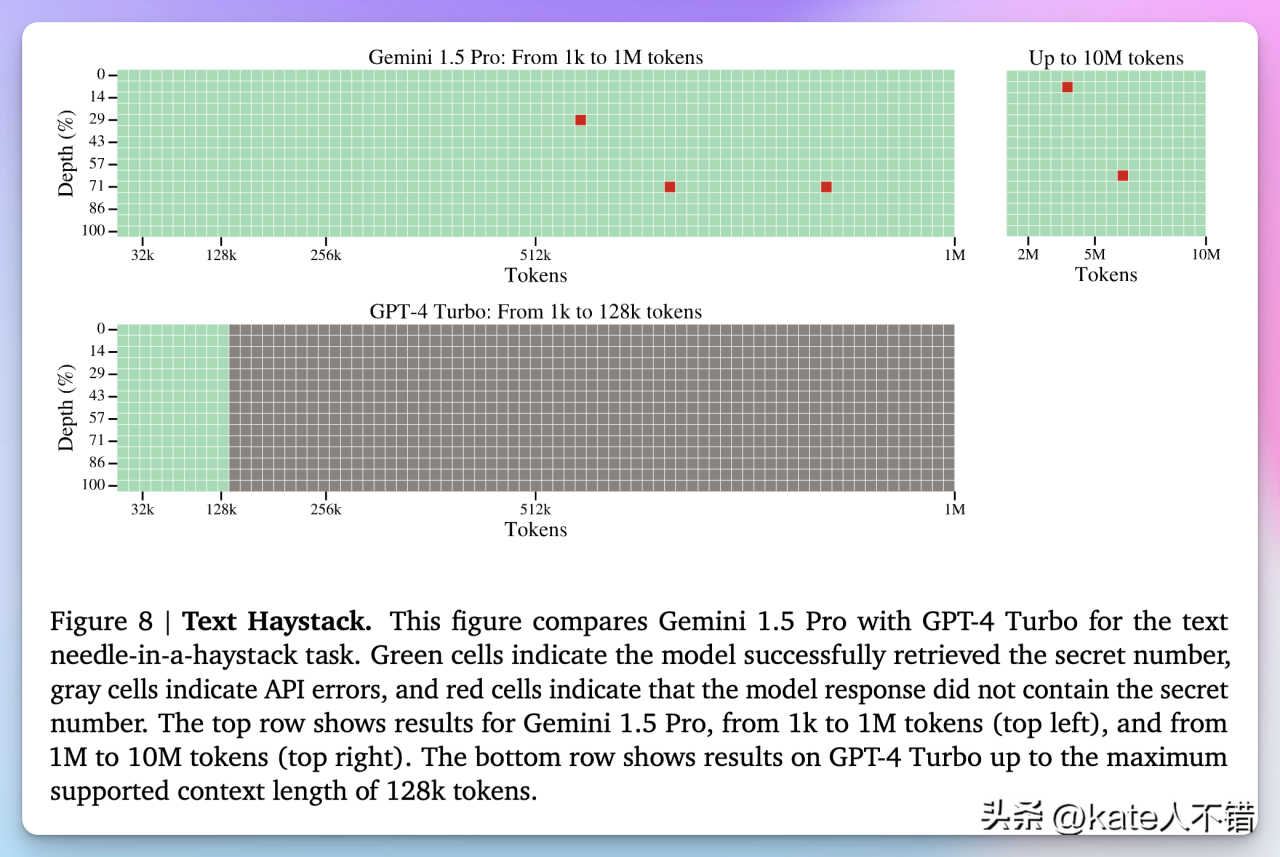
图 6:Gemini 1.5 Pro 和 GPT-4 Turbo 在文本检索任务中的表现
这张图片比较了 Gemini 1.5 Pro 和 GPT-4 Turbo 在文本检索任务中的表现。Gemini 1.5 Pro 在 1k 到 10M 标记范围内大部分成功检索目标信息,显示出强大的处理长文本能力。相反,GPT-4 Turbo 仅在 128k 标记范围内有部分成功,大量灰色方格表示出现 API 错误,未能完成任务。这展示了 Gemini 1.5 Pro 在长文本检索任务中的显著优势,相比之下,GPT-4 Turbo 的性能明显逊色。
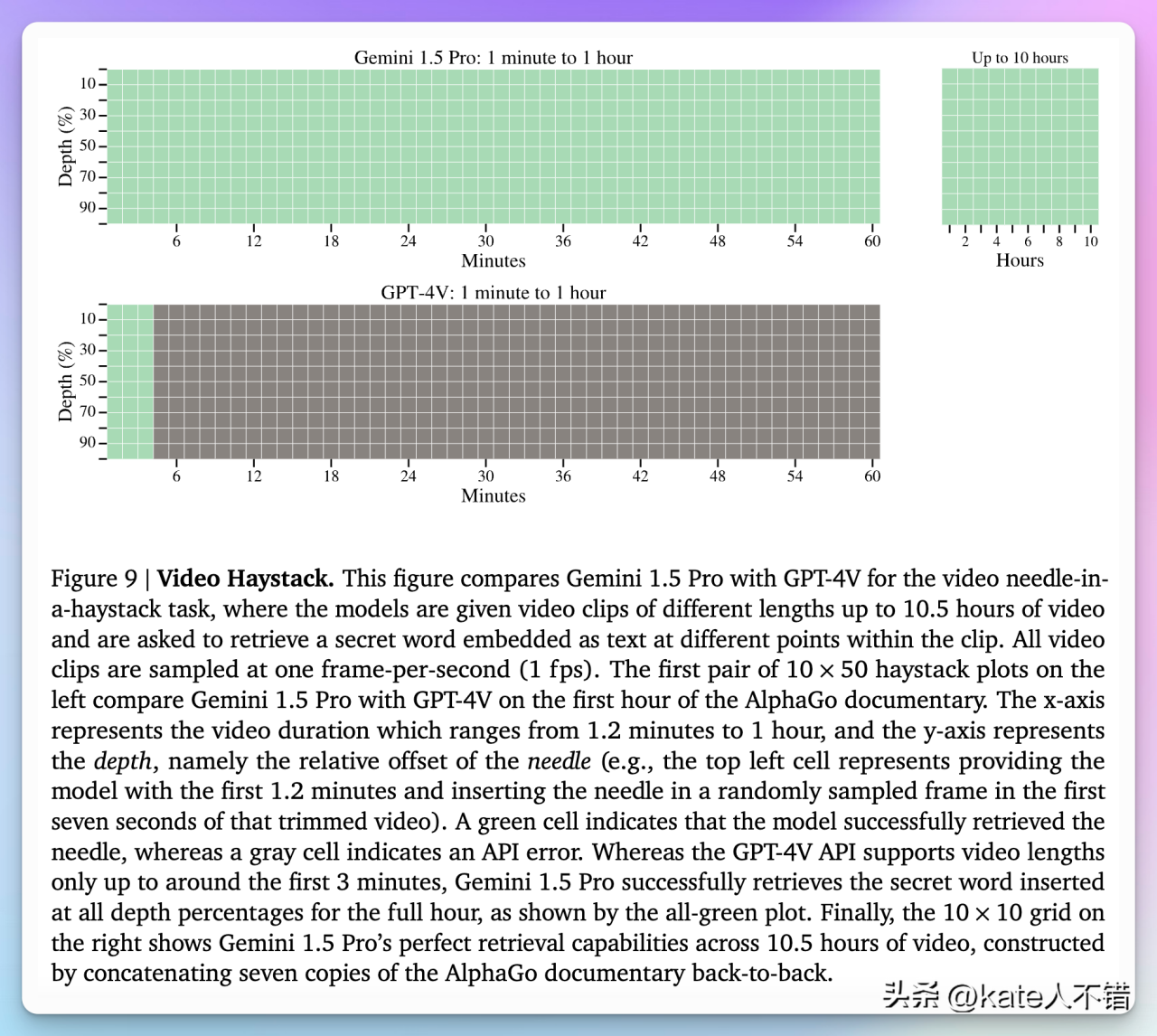
图 7:Gemini 1.5 Pro 和 GPT-4V 在视频检索任务中的表现
这张图片比较了 Gemini 1.5 Pro 和 GPT-4V 在视频检索任务中的表现。Gemini 1.5 Pro 能在所有视频长度中成功完成任务,包括最长的 10.5 小时视频,显示出其强大的长视频处理能力。相反,GPT-4V 只能处理最多 3 分钟的视频,超过 3 分钟即出现 API 错误,未能完成任务。绿色方格表示成功检索,灰色方格表示 API 错误。这展示了 Gemini 1.5 Pro 在长视频检索任务中的显著优势,而 GPT-4V 在处理长视频时表现不佳。