OpenAI和谷歌接连两场发布会,把AI视频推理卷到新高度。
但业界还缺少可以全面评估大模型视频推理能力的基准。
终于,多模态大模型视频分析综合评估基准Video-MME,全面评估多模态大模型的综合视频理解能力,填补了这一领域的空白。
Gemini 1.5 Pro在这份榜单中遥遥领先,显示出在视频理解领域的“霸主”地位。Video-MME一经推出,被谷歌首席科学家Jeff Dean连续转发了三次。
GPT-4o、谷歌Gemini 1.5 Pro标榜的视频推理能力终于在全新的、更复杂的多模态基准Video-MME上首次得到了验证。
同时,各大公司以及研究机构,例如NVIDIA、ByteDance等模型也加入了混战。
Video-MME由中科大、厦大、港中文等高校联合推出,代码和数据集均已开源。
全人工标注高质量数据集
该基准采取全人工标注,具有区别于现有数据集的显著特点。在以下的例子中,准确回答该问题需要同时从视觉、字幕以及音频中同时获取信息,有效信息直接横跨30分钟的间隔:
Video-MME具有以下显著特点:
时间维度的广泛性:视频时长从11秒到1小时不等,涵盖短(<2分钟)、中(4-15分钟)、长(30-60分钟)三种不同的视频时长,全面评估模型在不同时间跨度下的上下文多模态理解能力;
数据模态的丰富性:除了视频帧,Video-MME还整合了字幕和音频模态输入,全面评估大模型的多模态处理能力;
视频类型的多样性:覆盖了知识、影视、体育、艺术、生活记录和多语言6个主要领域,涉及30个细粒度子领域;
注释质量的高标准:900个视频,共254小时的内容由具备大模型背景的专业人员手动标注与验证,产生了2,700个问答对。问题类型涵盖感知、认知和总结概括等12种类型;
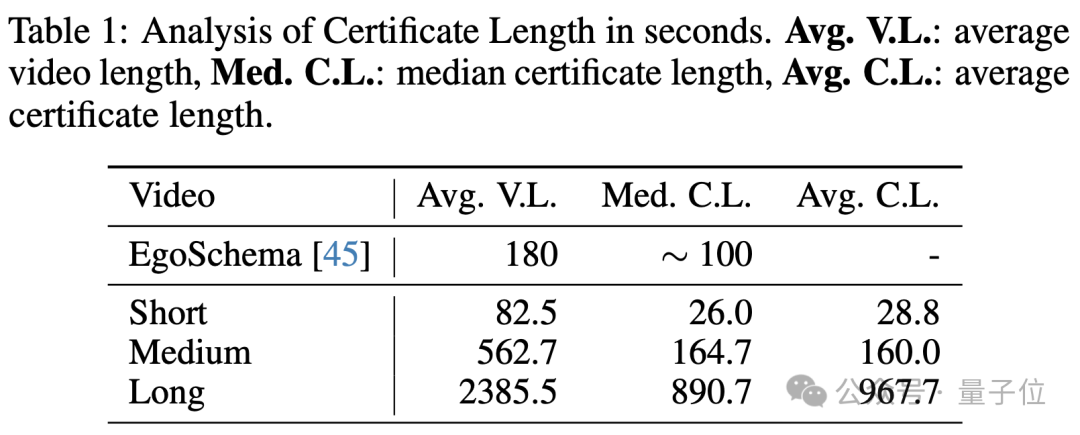
可靠的有效时长 (Certificate Length准确回答问题所需的最短时长):对于短视频、中视频和长视频,Video-MME数据集的有效时长中位数分别为26.0秒、164.7秒和890.7秒,要求模型消化更长的视频内容才能回答问题;
全面的实验评估:文章选取了6种代表性的开源视频语言模型以及闭源模型Gemini 1.5 Pro和GPT-4V/o进行全面的实验分析。同时文章还选取了基于图片的多模态大模型进行评测(泛化到多图输入),证明其同时适用于图片&视频多模态大模型。
文章选取了多种代表性的开源视频多模态大模型,包括ST-LLM、VideoChat2-Mistral、Chat-UniVi-V1.5、LLaVA-NeXT-Video和VILA-1.5,以及闭源模型Gemini和GPT-4V/o 。同时,基于图片的多模态大模型包括Qwen-VL-Chat、Qwen-VL-Max和InternVL-Chat-V1.5。
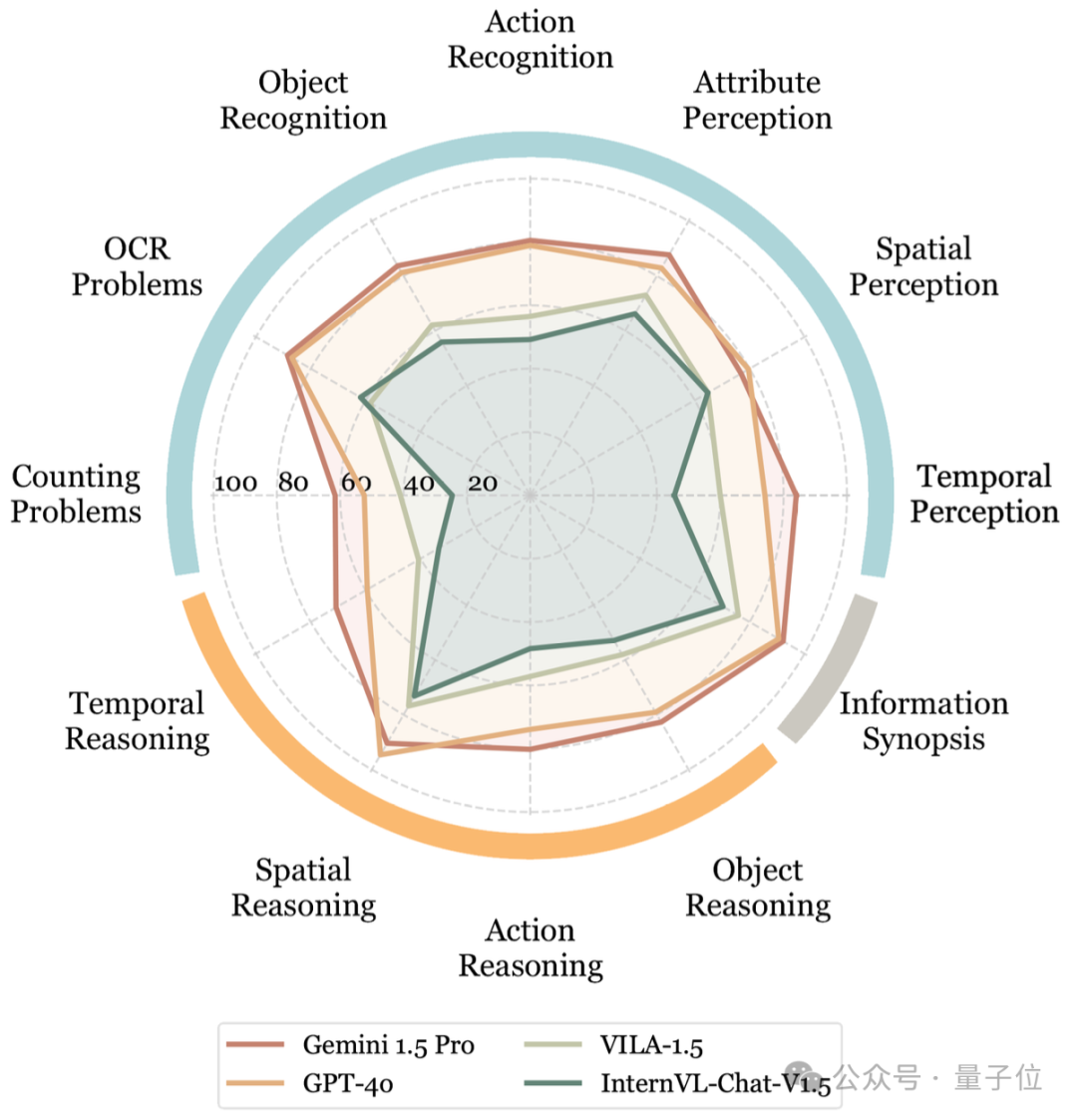
在商业模型中,Gemini 1.5 Pro在视频理解方面表现突出,在加以字幕辅助的情况下以81.3%的准确率领先,并在与GPT-4V和GPT-o的对比中分别超出18%和4.1%。
尽管随着视频时长增加,其表现略有下降,但在长视频上的表现(加字幕)优于所有开源模型在短视频上的表现。
同时,Gemini 1.5 Pro还支持音频模态的输入,模态支持的更广。而在开源模型中,来自NVIDIA的VILA-1.5以59.4%的准确率表现最佳。然而,相比Gemini 1.5 Pro,VILA-1.5在计数问题、动作识别和时间感知方面仍然存在显著差距。
同时,随着视频时长的增加,所有模型的表现均呈现明显的下降趋势,这也说明面对更长的上下文记忆以及更为复杂的任务时模型还有很大的提升空间。此外,实验还揭示了字幕和音频信息能显著增强视频理解能力,尤其是对于长视频的理解。
在三十种不同类型的视频上,Gemini 1.5 Pro展现出不同的性能。例如,有的任务对字幕和语音的依赖程度更高,如Basketball的长视频,加上字幕和语音能够显著提升性能。详细的实验结果请参照论文原文。
综合实验结果可以看出,当前的多模态大模型在视频理解,尤其是长视频理解方向仍然有很长进步空间,一方面是要提升模型的多模态长上下文理解能力,Gemini 1.5 Pro最高支持百万长度的上下文窗口,这是其表现优异的依仗,另一方面也亟需构建相应的高质量长视频理解数据集,这方面当下仍处于空白。