北京时间 12 月 6 日晚,Google 给近期稍显沉寂的 AI 模型战场扔下了一颗新的炸弹:号称多模态任务处理能力首次超越人类的 AI 模型,Gemini 1.0 正式发布。
在昨晚正式发布之前,外媒就有诸多关于 Google 这款全新 AI 模型的消息流出,Google 最早在今年五月的 IO 大会期间透露了 Gemini 的存在,但与之前外界预期的不同,Google 声称 Gemini 的发布并未因为任何内部原因而延期,表示其 AI 模型的研发进程从 2012 年已经开始,直到最近 2023 年发布 PaLM2 与 Bard 之后,就开始为 Gemini 的正式发布做准备。
DeepMind本就是 AI 领域顶尖研究机构,早在 OpenAI 踏入聚光灯下之前,DeepMind 就凭借 AI 围棋棋手 —— AlphaGo 赢得了全世界对 AI 时代的关注,如今名为「双子座」的新一代 AI 大模型正式对外发布,也颇有抢回 AI 模型领域主导地位的感觉:双子座在神话本身就对应着「快速思维」的能力,同时也有着包罗万象、善于沟通等寓意。
多模态能力
在实际表现上,Gemini 号称是史上第一款原生支持多模态能力的 AI 模型,换言之在 Gemini 之前的多模态 AI 模型,处理同时包括视频/文字/音频/照片两种以上的输入信息时,逻辑是分别训练不同模态对应的组件,然后将其理解出的语义拼接在一起,从而模拟人类在处理多模态场景问题时的反应。
这种架构虽然已经足够惊艳,但在面对复杂逻辑问题时难免会显得有些笨拙,因为在这种架构下 AI 模型的算力并未得到最高效的使用。Google 的解决方案则是将 Gemini 设计为原生多模态,从一开始就在不同模态上进行预训练。利用额外的多模态数据对其进行微调,以进一步提高其有效性。
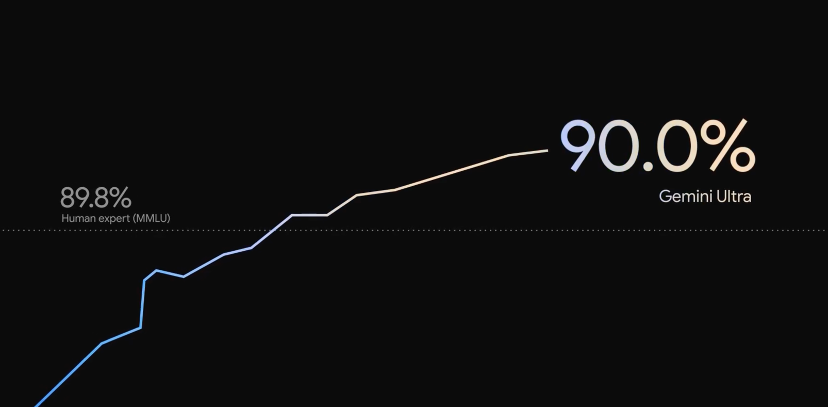
这种训练架构上的颠覆,让 Gemini 从最初的输入阶段就能对人类的的各种内容进行快速理解并推理,这一点在处理复杂问题上优势尤为突出:在发布 Gemini 的同时,Google 还宣布 Gemini Ultra 在行业标准 MMLU (多任务语言理解)基准测试中拿到了 90% 的成绩。
这不仅是 AI 模型有史以来第一次超越人类专家的测试结果,也超过了此前 GPT-4 同类测试中 86.5% 的结果。同时在九项独立基准测试中分别击败包括 LLAMA-2 GPT-4 在内的一众竞争对手。
Google也准备了几个演示场景,展示 Gemini 的多模态理解能力:视频中一位测试者正在用简笔画视频的方式,给Gemini 输入信息,在演示中 Gemini 能根据简笔画的每一笔改变,实时对最新的画面内容作出解读与描述。以及根据输入视频中出现的毛线颜色比例,给测试者推荐合适的编织玩具、以及跟 Gemini 玩猜硬币游戏,猜错了硬币在哪个手掌下之后,立即反应出这是测试者的把戏等场景。

同时处理多种形态的信息输入,是 Gemini 比起目前市面上其他的生成式 AI 模型最大的区别,在处理数学、计算机等复杂学科中这种优势能体现的更加明显,Google 也强调了 Gemini 在数学领域的复杂理解能力:在其中一个演示中,就展示了通过视频输入一道数学题,交由 Gemini 辅助解决的场景。
这样一个看似简单的需求中其实包括了对指令语义的准确理解以及手写图像识别,与此同时处理复杂逻辑的数学问题,这就是一个典型的多模态大模型应用场景。
可拓展性
到 2023 年下半年,不同体积的大模型并行发展已经成为行业主流,尤其是模型完全运行在本地的端侧大模型,更是生成式 AI 行业应用中炙手可热的前景。包括 vivo、小米 OPPO 等手机品牌都已经推出了面向普通智能手机用户的端侧大模型与云端大模型的结合应用。
Gemini也没有落下这一特征:在 Gemini 1.0 中,Google 一共发布了三个版本,其中 Gemini Ultra 最聪慧,但同时需要更大的计算量,Pro 是其中最均衡、适用于最多场景的版本,而 Nano 则是体积最小最高效的版本,同时也是主打部署在 Android 手机等设备上的端侧大模型。

Google并未直接向记者介绍 Gemini Nano 模型的体积,但据 DeepMind 介绍,Gemini Nano 具有完全在端侧离线运行的能力, 目前 Google 已经针对 Pixel 系统自带的录音 App 进行了 Gemini 的适配,即使没有网络连接,也能自动根据录制的对话、采访、演示等内容生成 AI 摘要。
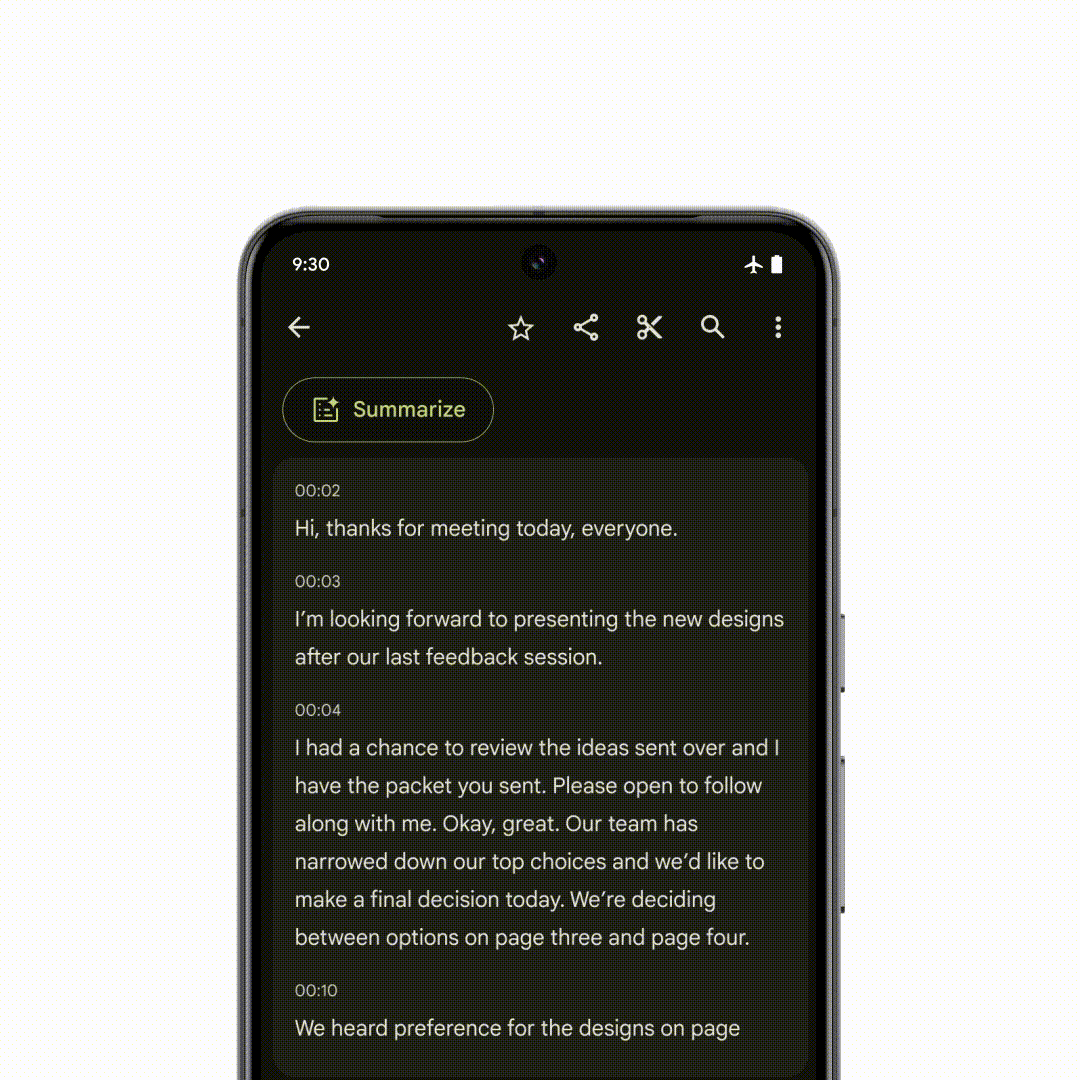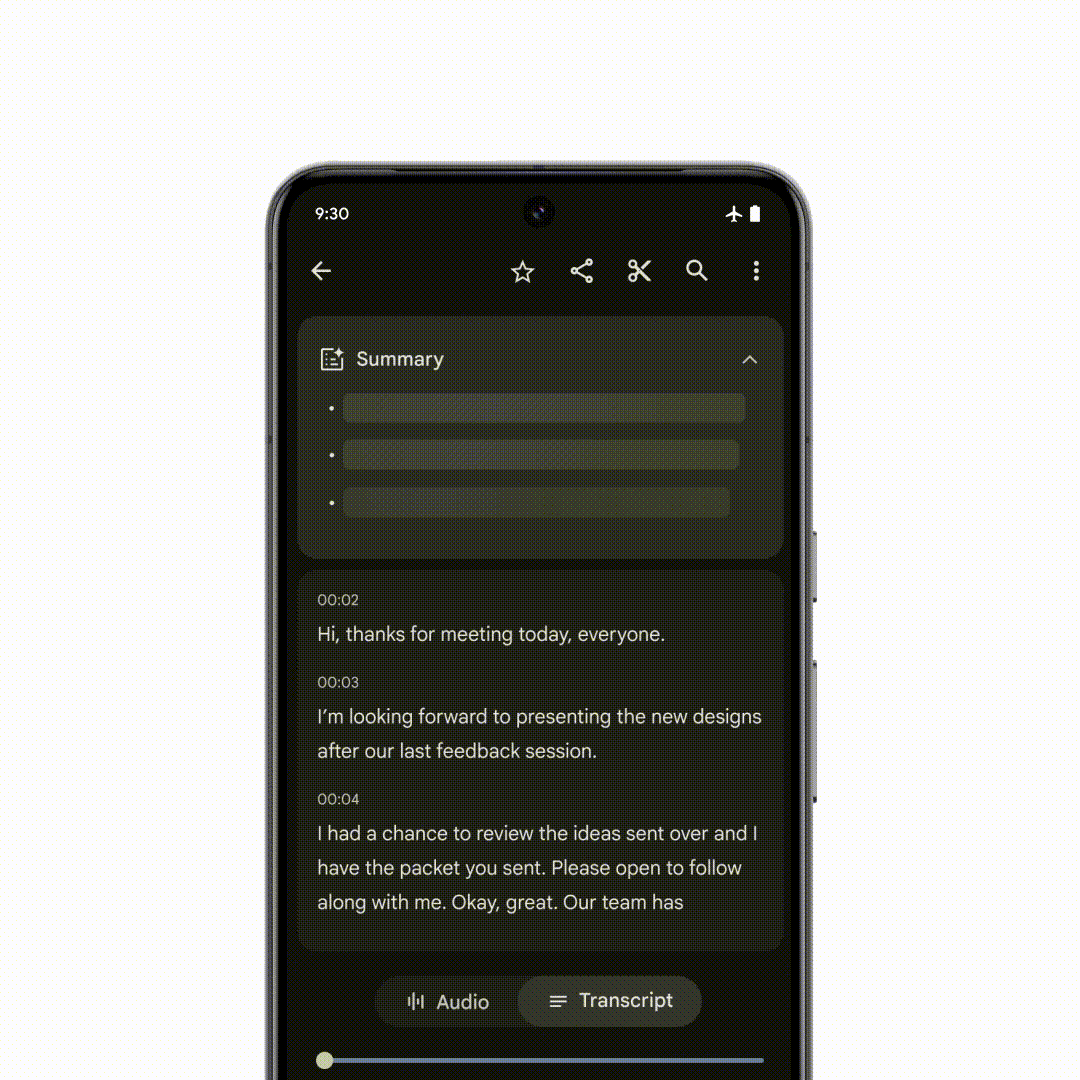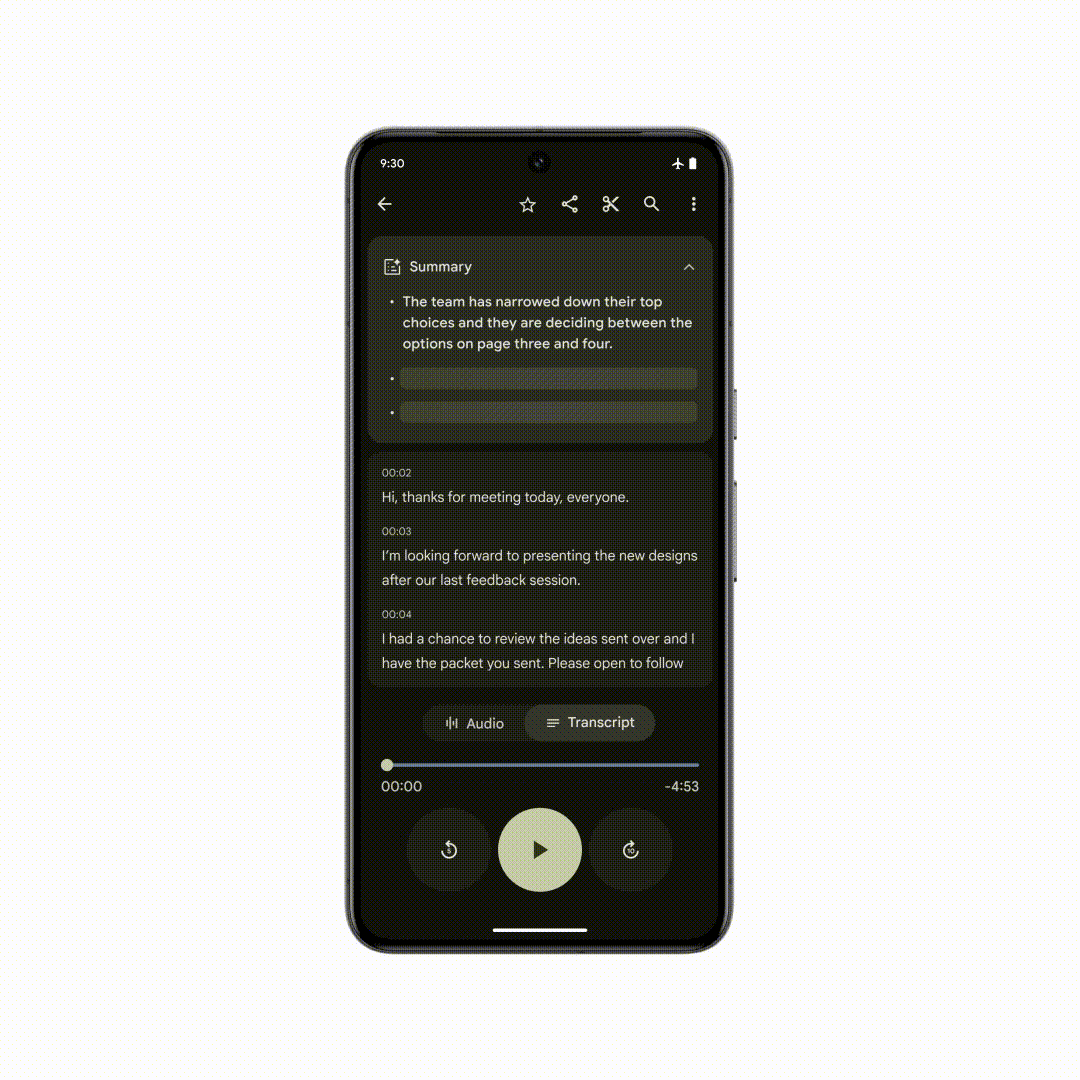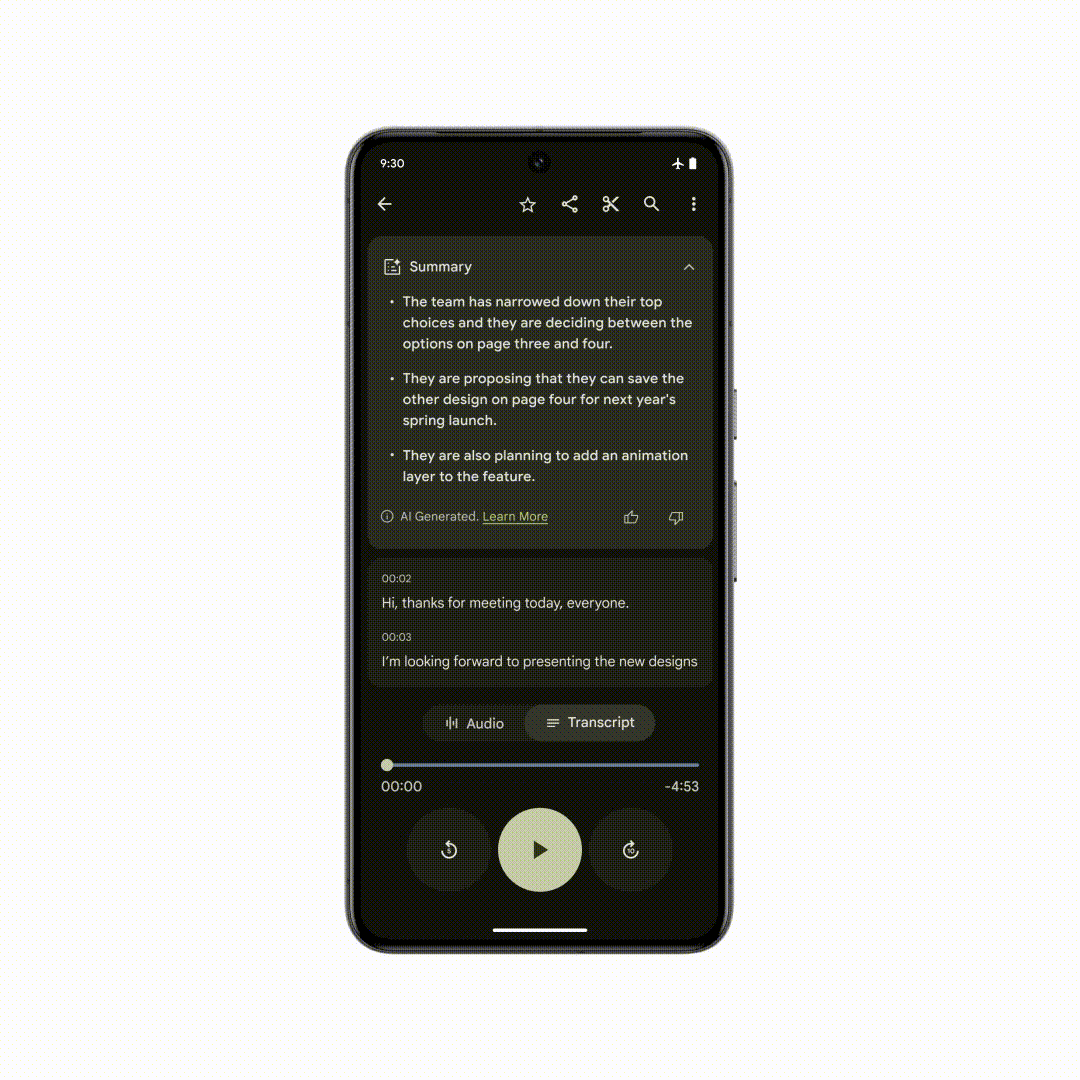
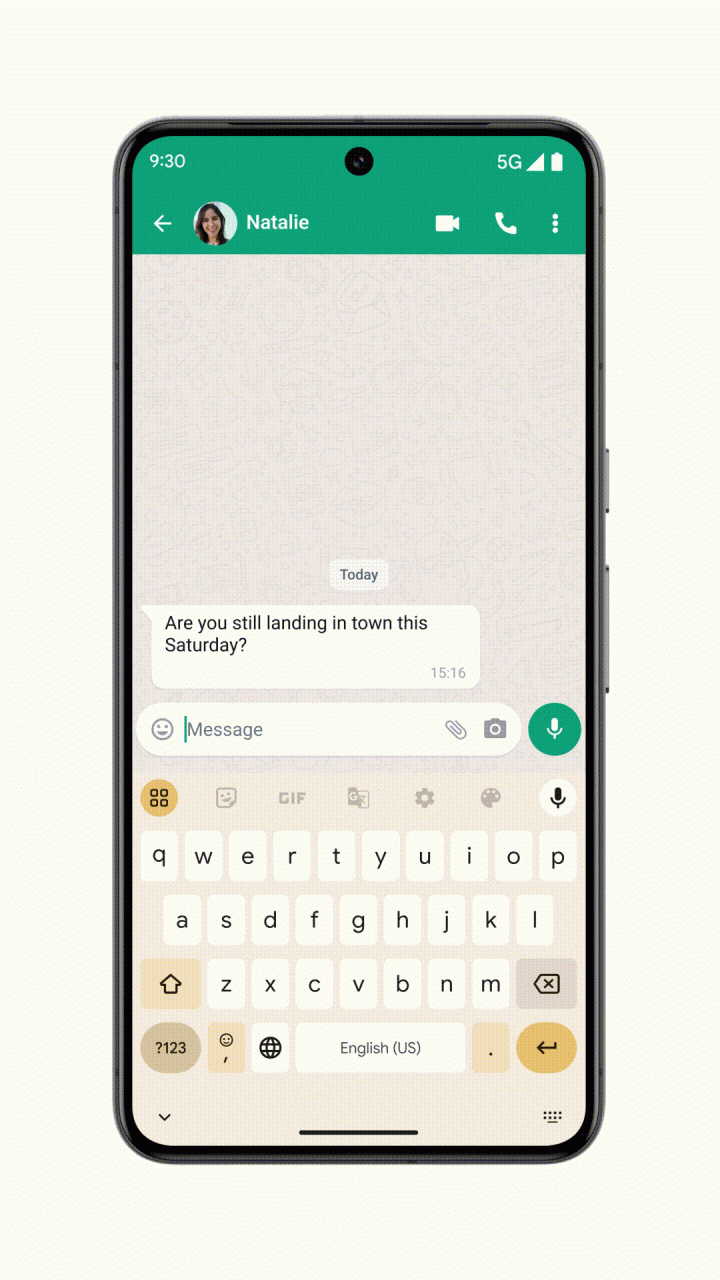
除了系统自带 App,Gemini Nano 的能力还被整合进 Android 系统中,第三方应用的开发者也能通过应用适配的方式调用手机自带的 Gemini 模型能力:例如手机自带的输入法能根据适配 Gemini 的聊天 App 中,对方发送给你的文字信息自动为你生成合适的快捷回复。
Google研发人员同时提到未来还有将 Gemini 登陆其他 Android 智能手机的计划,但这部分适配工作涉及到手机硬件的算力适配,因此目前暂时只有 Pixel 8 Pro 是 Gemini 的适配机型。
至于不少人关心的问题:Gemini 能完全超越 GPT 4.0 吗?记者现场也询问了 Google DeepMind 研发团队,虽然Google 并未正面回应这个提问,但重新强调了 Gemini Ultra 在 MMLU 中获得的评分相比 GPT-4 更高,也是目前唯一超越人类专家测试结果的 AI 模型。
新硬件,新架构
每次提到 Google 在生成式 AI 领域的硬件技术,往往少不了介绍 TPU(张量处理单元)的内容:这是 Google 专为开发神经网络机器学习的专用硬件,从 2015 年发布 TPU v1,迄今为止已经迭代了五个大版本。目前现阶段 Google 展示的 Gemini 1.0,就是基于 Google 数据中心的 TPU v4 和 TPU v5e 大规模阵列训练而来。
这些 TPU 阵列不仅用于训练 Gemini,它们也已经应用在 Gmail、YouTube、Google Play 等 Google 生态应用中有近十年的历史。同时也从 2018 年开始开放给第三方客户使用。也有不少人工智能初创公司选择其作为训练大模型的硬件基石。Google 同时也提到在 TPU 上,Gemini 的运行速度也明显优于早期体积较小的模型。
如今 AI 模型参数仍然在呈指数级增长 —— 顶级的 AI 大模型已经拥有数千亿甚至是万亿级参数,即使是最顶级的 GPU 配置搭配不差钱地堆砌 GPU 数量,训练出如 GPT-4 这样的大模型也需要长达数月以上。可以说高性价比的高算力平台,是目前行业内最迫切的需求。因此适用于下一代 AI 训练的硬件架构其实也已经呼之欲出:在发布 Gemini 1.0 的同时,Google 同时向外界展示了最新的 TPU v5p 系列。