刚刚Google正式发布其最新研发的多模态大模型Gemini,这不仅是技术的一次革新,也是对现有AI领域,尤其是GPT-4的一次重大挑战。

让我们一起来探索Gemini的独特之处和其对未来可能产生的深远影响。
Gemini的三重构成:多样化的AI体验
Gemini的设计思路非常独特,它包含三个不同的模型:Ultra、Pro和Nano。这三个模型针对不同的应用场景和需求进行优化,从而提供更加个性化和高效的AI体验。

Gemini Ultra
专注于处理复杂的任务,如高级科学研究、复杂的数据分析等。
Gemini Pro
适用于广泛的任务范围,从日常问题解答到业务流程优化。
Gemini Nano
为设备端高效任务设计,如智能手机上的实时语音识别和图像处理。
多模态与实时交互:Gemini的核心优势
Gemini的一个核心优势在于其多模态能力。它能够理解和处理图像和语音数据,这使得它能在提供文字答案的同时,还能理解图表和进行实时语音交流。这种能力大大扩展AI在不同领域的应用潜力。
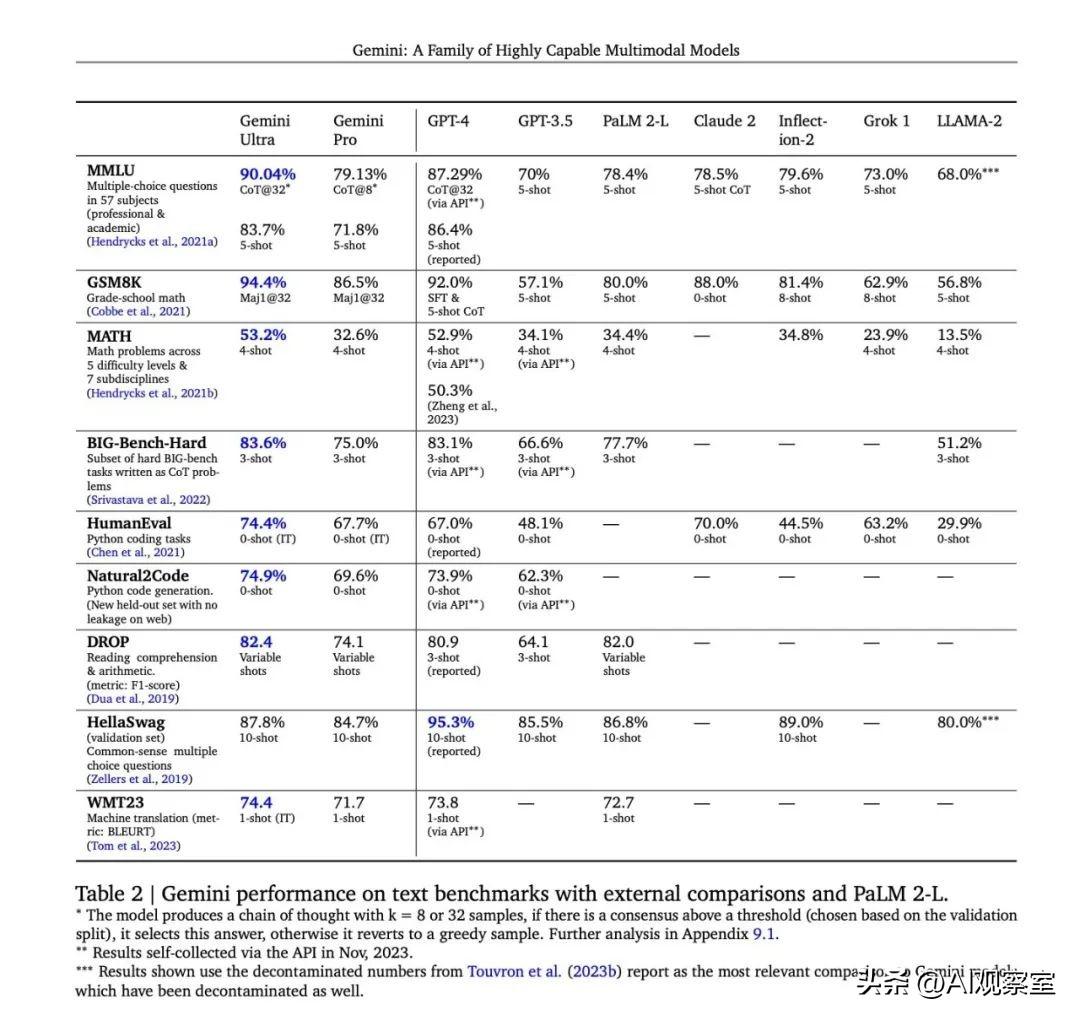
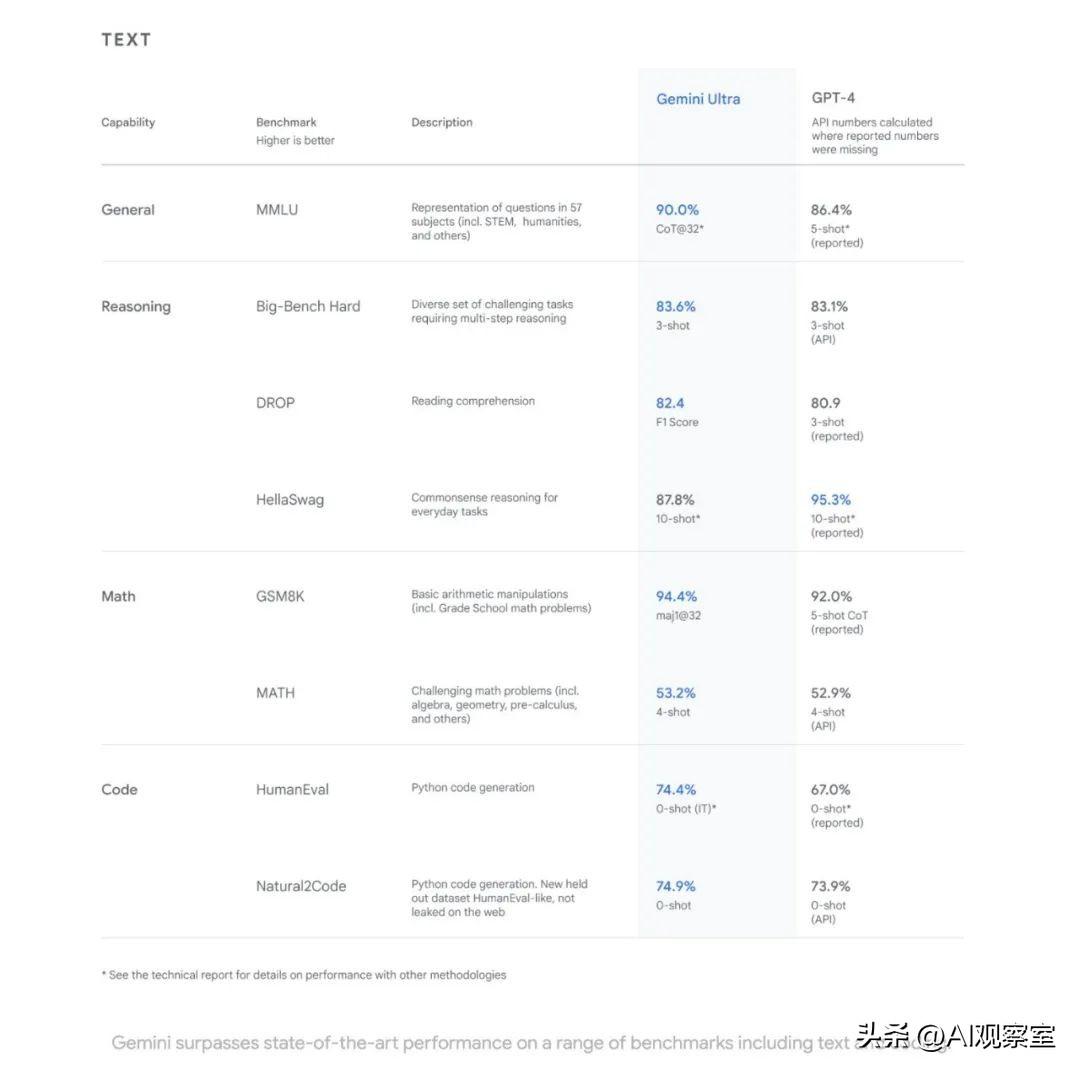
基准新高:Gemini Ultra的突破
在MMLU基准测试中,Gemini Ultra以90%的成绩超越了人类专家,这在AI领域是前所未有的。它的出现标志着AI技术在理解复杂问题和提供高质量解决方案方面迈出了重要一步。
Gemini的高级应用:从科学到数学
除了传统的语言理解能力,Gemini在科学、数学和编程等领域表现出色。相比于ChatGPT(GPT-4),Gemini在处理更复杂的科学问题和编码任务上显示了更高的能力,这对于科研工作和技术开发来说是一个巨大的进步。
Gemini Pro和Ultra:广泛的应用前景
Gemini Pro将在Bard和其他Google产品中免费提供,它在八项基准测试中的六项上超越了GPT-3.5,被誉为“市场上最强大的免费聊天AI工具”。
而Gemini Ultra将在明年初推出,预计将在AI研发的32个基准测试中的30个上超越当前的最高成绩。
Gemini Nano:智能手机上的应用革命
Gemini Nano将应用于即将发布的Pixel 8 Pro,为用户提供包括智能摘要、智能回复、先进的视频处理技术以及增强的摄影和图像编辑功能。
最后结语
Google的Gemini模型不仅是对GPT-4的强劲挑战,更代表了AI技术的新高度。
从多模态交互到高级科学计算,从设备端的高效运行到广泛的应用整合,Gemini定义了AI技术的未来方向。
让我们拭目以待,看看Gemini将如何重塑我们的数字生活和工作方式。