丢出一枚“延迟发布”烟雾弹后,谷歌出其不意,在深夜憋了个大的,于当地时间12月6日提前发布了自研大模型Gemini——ChatGPT的最有力竞争对手。
Gemini实际上是一个人工智能模型家族: “大杯”Gemini Ultra、“中杯”Gemini Pro、“小杯”Gemini Nano,都支持上下文32K理解。

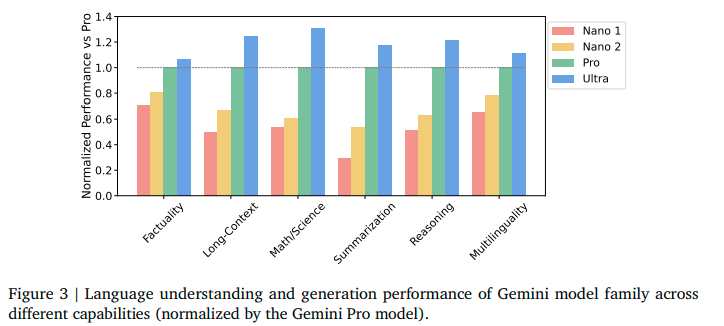
Gemini三种版本的能力对比图
其中,Gemini Ultra主要是为数据中心和企业应用设计,以其强大的原生多模态性能,再次引发了大家对通用人工智能的想象。
▌原生多模态碾压ChatGPT
多模态从一开始就是谷歌大模型框架的一部分。
OpenAI当下最强大的大模型GPT 4也号称多模态模型,它是怎么实现的呢?不是直接训练一个多模态模型,OpenAI先分别训练了纯文本、纯视觉和纯音频模型,然后将他们拼接在一起。
而谷歌从一开始就建立了一个“多感官”模型,给其“投喂”多模态数据(包括文字、音频、图片、视频、PDF文件等)进行训练。随后,研究人员又用额外的多模态数据进行了微调,进一步提升了模型的有效性。
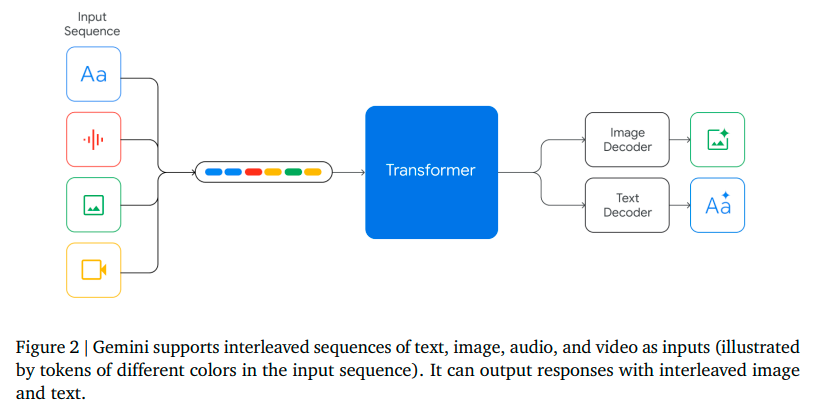
Gemini支持输入文本、图像、音频和视频,输出图像和文字
基于此,谷歌称其多模态为原生多模态(natively multimodal),可以“无缝”理解、操作和组合不同类型的信息,拥有了强大的交互能力。
为了证明自己的产品比OpenAI的ChatGPT更出色,谷歌甩出了数张成绩单。
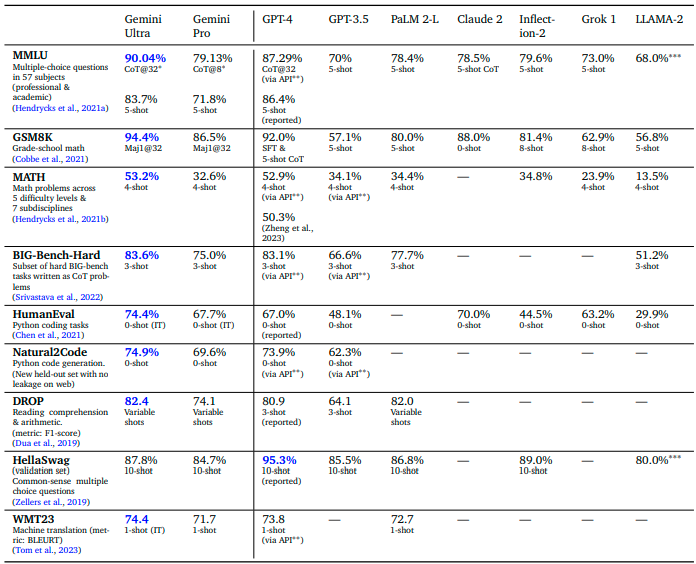
据谷歌介绍,从自然图像、音频、视频理解到数学推理,Gemini Ultra在32个常用的学术基准的30个上领先GPT 4。而在MMLU(大规模多任务语言理解)测试中,Gemini Ultra以90.0%的高分,成为第一个超过人类专家的模型。
MMLU测试包括数学、物理、历史、法律、医学和伦理等57个学科,旨在考察世界知识和解决问题的能力。
▌多模态的意义——为人形机器人铺路 更贴近AGI
通用人工智能(AGI)是具备与人类同等智能、或超越人类的人工智能,实现通用人工智能是AI领域的终极目标。这样的AI可以实现自我学习、自我改进、自我调整,进而解决任何问题而不需要人为干预,拥有多模态能力是前提条件。
谷歌DeepMind已经在研究如何将Gemini与机器人技术结合起来,与世界进行物理交互。据Wired报道,DeepMind首席执行官、Gemini团队代表德米斯•哈萨比斯(Demis Hassabis)表示,真正的多模态需要包括触摸和触觉反馈,将这类多模态模型应用于机器人技术能催生很多可能性,“随着时间的推移,Gemini的多模态能力将提升,其将获得更多的感官,包括触觉,我们正在对此进行深入探索。”
这意味着,Gemini可以真正用人类的方式理解周围的世界,接收各种类型的数据,包括文字、代码、音频、图像、视频,并给出同样多样化的响应,包括操纵机械臂给出动作回应,人类离通用人工智能更近了一步。
▌用于端侧设备的最高效模型 可在安卓设备上本地离线运行
谷歌表示,Gemini还是他们迄今为止最灵活的模型,能够高效地运行在数据中心和移动设备等多类型平台上。
端侧运行任务交给了Gemini Nano。Gemini Nano是通过对其他模型蒸馏得来的4位模型,号称用于端侧设备最高效的模型,可以在安卓设备上本地离线运行,Pixel 8 Pro的用户马上就能体验到。Gemini Nano有两种型号,Nano-1(18亿参数)和Nano-2(32.5亿参数)——分别针对低内存和高内存设备。