12月6日,谷歌宣布推出其最强人工智能模型Gemini(/dʒɛmɪnaɪ),诞生快一年的GPT4终于迎来了第一个挑战。
还没看过演示的,建议搜搜人类和Gemini互动的演示视频。演示中,Gemini带摄像头,可以输出文字、图像和声音。
概要说下Gemini的三大关键特性。
原生多模态
原生多模态就是大模型一开始训练的时候就同时支持文本、语音、图像、视频等不同类型的输入。与之相对应的就是单模态,比如只支持文字输入输出。
更直白的说,Gemini是一个更像人类的大模型,像是有人眼和耳朵一样,可以理解图像和声音。要特别注意,它对于声音的理解是原生的。就是说Gemini可以听得懂原生声音,而不是把声音翻译成文字去理解。所以,它可以理解你声音的语调甚至情绪。而对于视频的理解也是GPT4都不具备的能力。
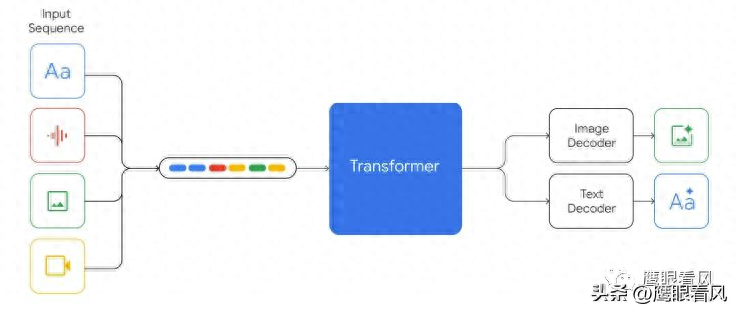
重磅来了,Gemini是第一个在大规模多任务语言理解上超越人类专家的大模型。虽然只超越了一点点,但是仍然是首个。
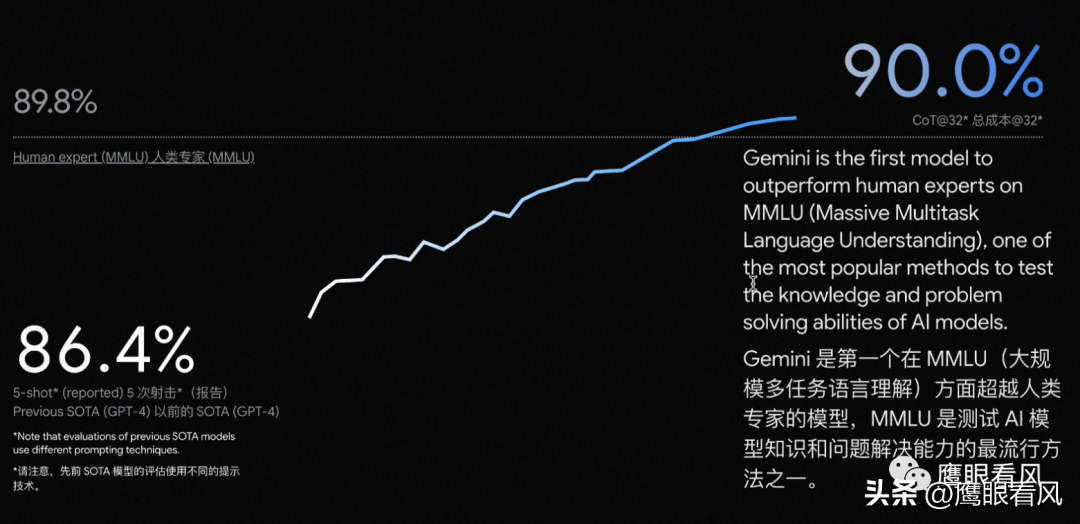
多种规格
Gemini将包括三种不同的套件:Gemini Ultra,Gemini Pro和Gemini Nano,性能依次递减。
Gemini Ultra:最大、最有能力处理高度复杂任务的型号,略胜对标的GPT-4,但目前并未对外推出。
Gemini Pro:在各种任务中扩展的最佳模型,大幅领先对标的GPT-3.5,Bard 已经部署使用,12 月 13 日起开发者可以访问 API。
Gemini Nano:高效的设备端任务模型,用于在手机端侧运行。
超越GPT4
Gemini是不是比GPT4更强呢?这可能是大家最关心的点。先说我的判断,半斤八两,不同领域各有所长。
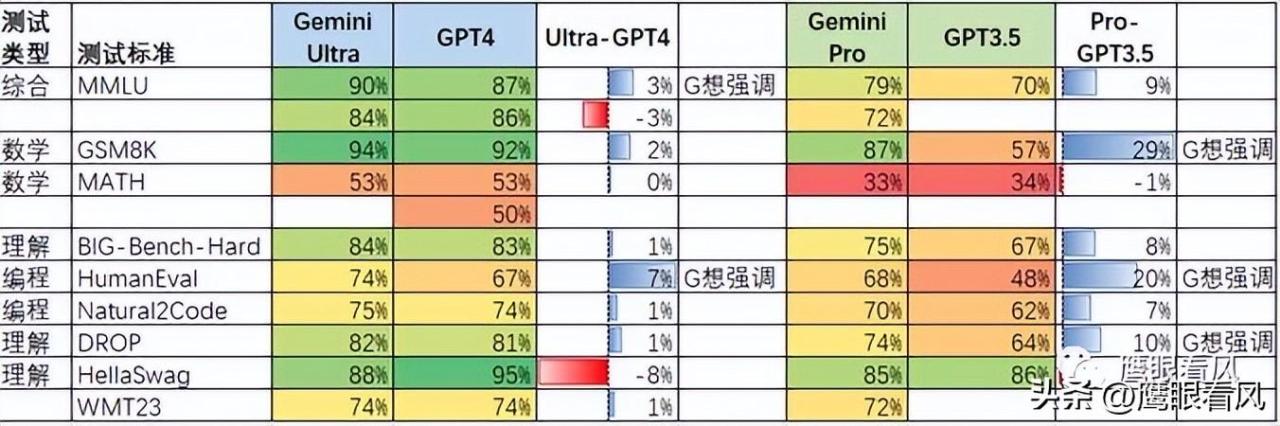
来看下比较受认可的测评,在大部分领域里面,Gemint Ultra表现略优于GPT-4。这个模型使用了数学、物理、历史、法律、医学、伦理等57个学科的组合。
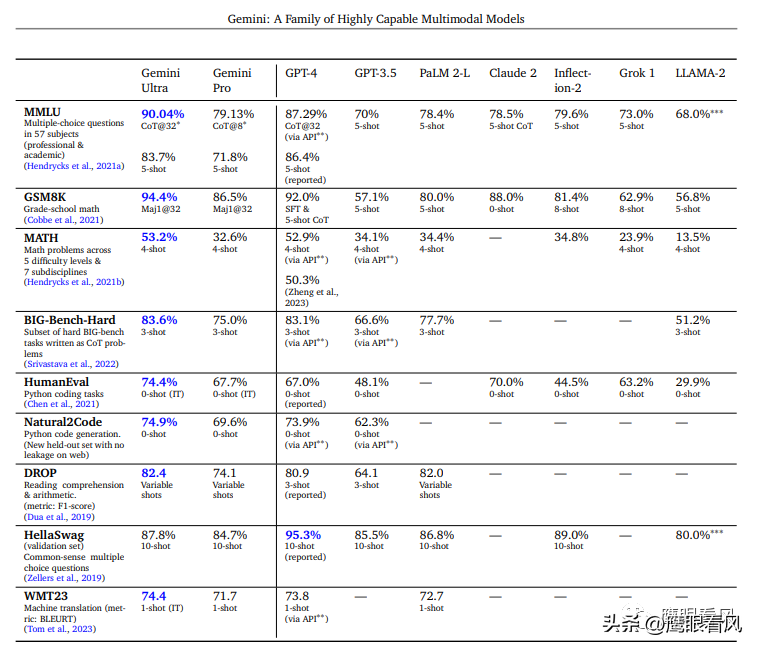
英文看不了就看这个中文的。
Gemini Ultra略优于GPT4,尤其在编程方面,大幅优于GPT4。Google不愧是传统老牌码农圣地。Gemini ultra 是全网最强码农。Gemini Pro则大幅超越GPT3.5。
Gemini现在还无法体验。
如果你连GPT4或者GPT3.5都还没有体验过,那真的有点落后时代了。赶紧上“无涯助理” wx晓城序体验一下吧。
几点感悟
Gemini和GPT谁更强,还会有持续的争论。上面的视频确实有修饰成分。但是无可争议的是,除了OpenAI之外,终于有一家公司研发出来可以和GPT4并驾齐驱的大模型。说明,大模型是一条可见有多路径实现成功的方向。
原生多模态天生就优于单模态,从方案来说,Gemini就超过了GPT。原生多模态应该会是大厂重点发力的方向。
谷歌的Gemini是基于google自研的TPU训练的,也就是说谷歌是在没有英伟达的帮助下完成的大模型。这才叫大厂呀,芯片都自己开发的。国内的大厂,差距真的有点远呀。只有华为有一战之力。

大模型仍然在飞速前进,很多创业公司的投入注定是收不回成本的。蛋糕的大部分大概率仍然是几个寡头的。

大模型已经火爆一年多,总是说要颠覆现在的各大行业,但是总是让人感觉差那么点,有希望但是感受还不明显。但是Gemini让我更加确认,大模型还差一个奇点时刻,一旦突破就会横扫。而且这个奇点越来越近的。 就像Gemini更像人了,我们离通用人工智能又近了一步。