谷歌的演示视频似乎暗示:当Gemini实时观察周围的世界并做出反应时,人可以与Gemini进行流畅的语音对话。但实际上,演示中的声音是在读出人向Gemini发出的文本提示,并识别人展示的静态图像,且响应时间比视频中展示的时间长。
·谷歌DeepMind强调,Gemini是人工智能的新品种——“原生多模态”,区别于现有的“拼凑多模态”模型,即从一开始就使用多种模态(例如音频、视频和图像)训练而成。因此,Gemini开辟了一条人工智能领域前所未见的道路,可能会带来重大的新突破。

Alphabet首席执行官桑达尔·皮查伊在2023年5月的Google I/O开发者大会上首次提到Gemini。
谷歌备受瞩目的新AI模型Gemini刚刚发布,就引发了一些争议。
有媒体报道称,一段由人工智能开发机构谷歌DeepMind制作的演示视频夸大了Gemini的性能。这段视频在网络上广泛流传,显示Gemini能够迅速判断画面中的实物并给出像人一样的语音反馈,凸显出惊人的多模态功能。但一些媒体和用户在亲自上手使用时发现,Gemini并不能达到视频中的效果。事实上,谷歌DeepMind承认演示不是实时或以语音进行的。这种营销努力甚至遭到了谷歌内部员工的批评。
随着中等版本的Gemini Pro开放使用,越来越多用户在网上发布测评,一些用户对其早期印象并不好,尽管其确实改进了谷歌聊天机器人Bard的性能。而对标GPT-4的高级版本Gemini Ultra要到明年才发布。
值得注意的是,谷歌DeepMind首席执行官德米斯·哈萨比斯(Demis Hassabis)在接受媒体采访时强调,Gemini是人工智能的新品种——“原生多模态”,区别于现有的“拼凑多模态”模型,即从一开始就使用多种模态(例如音频、视频和图像)训练而成。因此,Gemini开辟了一条人工智能领域前所未见的道路,可能会带来重大的新突破。
“只是为了简洁而缩短了”
彭博社专栏作家帕米·奥尔森(Parmy Olson)12月7日撰文称,第一次观看谷歌DeepMind关于Gemini的视频演示时,确实大受震撼。Gemini能够从塑料杯下追踪盖住的纸团,或者通过白色的点推断出将画出什么图形,这显示了DeepMind人工智能实验室在过去几年中培养的推理能力,这是其他人工智能模型所缺少的。但所展示的许多其他功能并不是独一无二的,正如沃顿商学院教授伊桑·莫利克(Ethan Mollick)所演示的,可以通过ChatGPT Plus复制。
02:35
谷歌DeepMind关于Gemini的视频演示。(02:35)
这段演示也不是实时或以语音进行的。谷歌发言人承认,该视频“使用镜头中的静态图像帧并通过文本提示”制作。该公司指出,有一个网站展示了如何通过双手、图画或其他物体的照片与Gemini互动。换句话说,演示中的声音是在读出人向Gemini发出的文本提示,并识别人展示的静态图像。而谷歌视频中暗示的似乎不同:当Gemini实时观察周围的世界并做出反应时,人可以与Gemini进行流畅的语音对话。
当然,谷歌其实已经表明该视频经过编辑。“出于本演示目的,为了简洁起见,延迟已经减少,Gemini输出(时间)也已缩短。”该公司在其YouTube视频的描述中表示。这意味着模型每个响应所花费的时间实际上比视频中展示的时间长。
这段视频也没有具体说明该演示是否使用了尚未发布的Gemini Ultra——Gemini中最大、功能最强的类别,被定位为GPT-4的竞争对手。
谷歌DeepMind产品副总裁伊莱·柯林斯(Eli Collins)告诉媒体,视频中的画鸭子演示仍然是研究级别的功能,至少目前还没有出现在谷歌的实际产品中。
一位谷歌员工告诉彭博社,他们认为这段视频描绘了一幅不切实际的画面:让Gemini取得令人印象深刻的成绩是多么容易。另一位员工表示,对演示并不太感到惊讶,因为他们已经习惯了公司公开定位其产品的某种程度的营销炒作。“我认为大多数使用过大语言模型技术的员工都知道要对这一切持保留态度。”该员工说。
科技媒体The Verge的编辑认为,企业经常编辑演示视频,特别是因为许多公司希望避免现场演示带来的任何技术问题,稍微调整一下是很常见的。但谷歌有制作可疑演示视频的历史,比如,可以打电话给理发店和餐馆进行预约的人工智能语音助手Duplex的演示就曾引起怀疑。而预先录制的人工智能模型视频往往会让人们更加怀疑。
奥尔森则认为,谷歌是在“炫耀”,目的是误导人们,让他们忽视Gemini仍然落后于OpenAI的事实。“捏造这些细节表明了更广泛的营销努力:谷歌希望我们记住,它拥有世界上最大的人工智能研究团队之一,并且比其他任何人都能获得更多的数据。”奥尔森写到,“几乎可以肯定,谷歌的炫耀是为了利用OpenAI最近的动荡。”
谷歌DeepMind研究和深度学习负责人副总裁奥里奥尔·维尼亚尔斯(Oriol Vinyals)在一篇帖子解释了团队是如何制作该视频的。“视频中的所有用户提示和输出都是真实的,只是为了简洁而缩短了。”维尼亚尔斯说,“该视频展示了使用Gemini构建的多模态用户体验是什么样子。我们这样做是为了激励开发人员。”
这个回应遭到了The Verge编辑的批评:“这当然是解决这种情况的一种方法,但对谷歌来说可能不是正确的方法——至少在公众看来,谷歌已经被OpenAI今年的巨大成功打了个措手不及。如果它想激励开发人员,就不能通过精心编辑的、可能歪曲人工智能能力的精彩视频。”
第一波测试结果
那么,Gemini的性能到底怎么样呢?一些媒体和专业人员已经展开了测评。
Gemini的中等版本Gemini Pro在发布当天通过聊天机器人Bard推出,没过多久,用户就开始在X(前身Twitter)上表达他们的不满。
在某些案例中,该模型未能正确反映基本事实,例如2023年奥斯卡获奖者。Gemini Pro错误地声称最佳男主角是布兰登·格里森(Brendan Gleeson),而不是真正的获胜者布兰登·弗雷泽 (Brendan Fraser)。
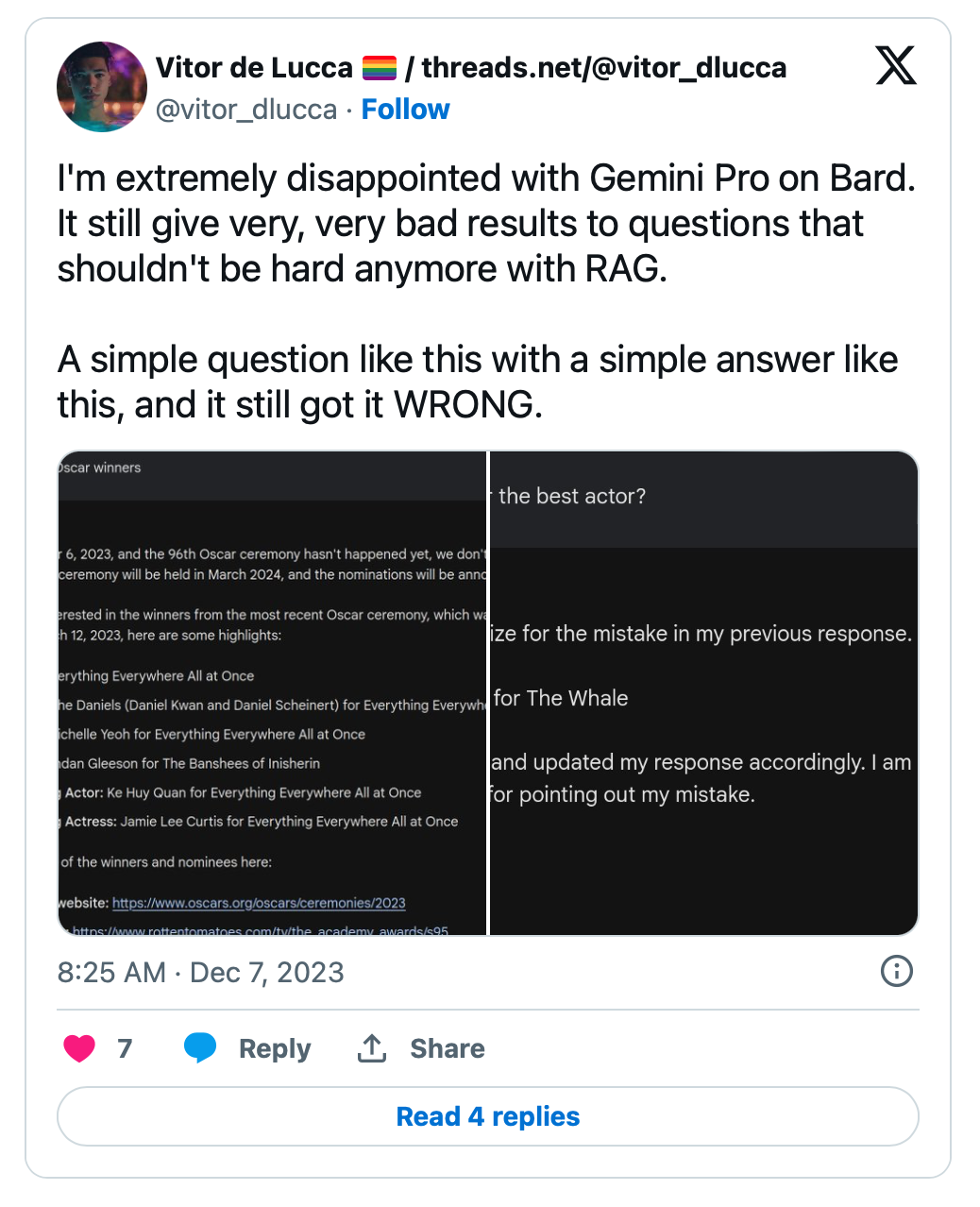
Gemini Pro说错了奥斯卡奖得主。
当再次向模型询问同样的问题时,它给出了不同的错误答案:
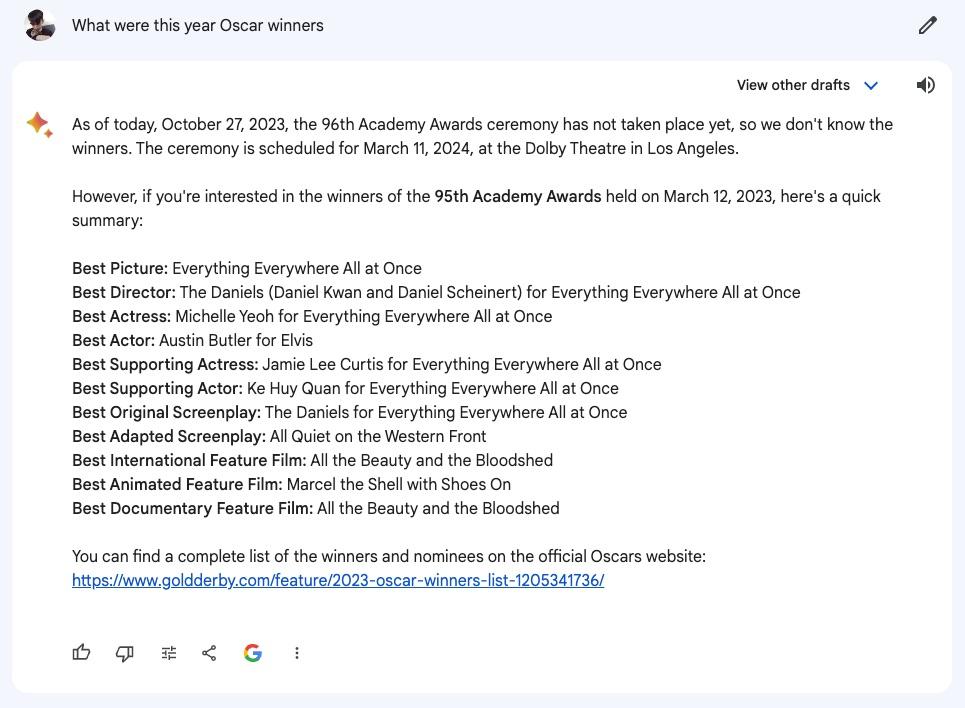
科幻小说作家查理·斯特罗斯(Charlie Stross)在一篇博客文章中写道,发现了更多Gemini Pro虚构事实的例子。
翻译似乎也不是Gemini Pro的强项。当要求它用法语给出一个6个字母的单词时,它给出了一个5个字母的单词。当TechCrunch记者提出同样的要求时,Gemini Pro回答了一个7个字母的单词。