12/6,谷歌发布大模型Gemini,在Gemini Technical Report中声称Ultra版在绝大部分测试中优于GPT-4,但目前只向用户开放性能较弱的Pro(性能介于GPT-3.5和GPT-4之间)和Nano(手机用)。当前北美大模型竞争格局逐渐明朗,微软+OpenAI在商业化和用户认知度上领先一步,Meta通过开源模型LlaMa-2吸引大量开发者,在大模型投入最早的谷歌却在模型能力、商业化、生态上都缺乏特色,谷歌采取逐步方式(Phased approach)提早发布Gemini或部分反映了公司面临的竞争压力。建议关注后续Gemini和搜索、手机、云等主要业务如何结合,以及Ultra的发布进度。
Gemini:原生多模态模型,三个不同规模的模型适用不同场景
目前创建多模态模型时,往往分别训练不同模态的模型并加以拼接,Gemini 是原生多模态模型(文本、代码、音频、图像和视频),一开始就在不同模态上进行预训练,因此能够对输入的各模态内容顺畅地理解和推理,效果较优。Gemini包括三个不同规模的模型:1)Ultra是规模最大且功能最强大的模型,适用于高度复杂的任务。2)Pro适用于各种任务的最佳模型。3)Nano是端侧设备上最高效的模型。谷歌未公开Gemini Ultra及Pro的参数规模,仅公开了Nano拥有1.8B、3.25B参数的两个版本。
Gemini生态:C端落地Bard、Pixel手机、搜索等产品,B端将推出API
谷歌将在聊天机器人、手机等产品和服务中落地Gemini:1)Bard将使用Gemini Pro的微调版本来进行更高级的推理、规划和理解等。2)Pixel 8 Pro是首款搭载Gemini Nano的智能手机,它可以支持录音应用中的“总结”等新功能,并在Gboard中推出“智能回复”功能,从WhatsApp开始,明年还将推出更多信息应用。3)未来几个月,Gemini将应用于谷歌更多的产品和服务,如搜索、广告、Chrome和Duet AI。4)从12月13日开始,开发者和企业客户可以通过Google AI Studio或Google Cloud Vertex AI中的Gemini API获取Gemini Pro。
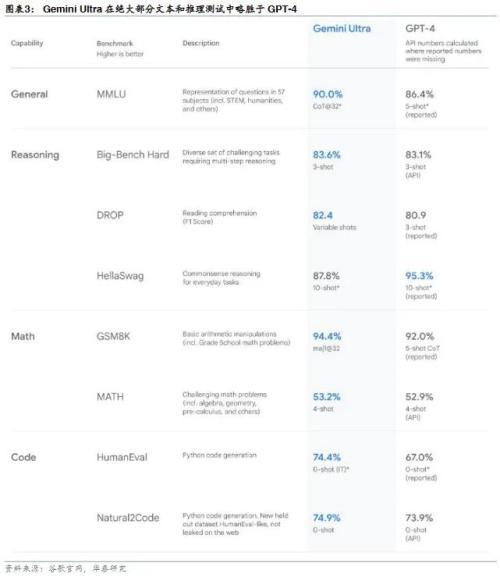
Gemini Ultra:文本和推理能力略胜于GPT-4,图像理解能力略胜于GPT-4V
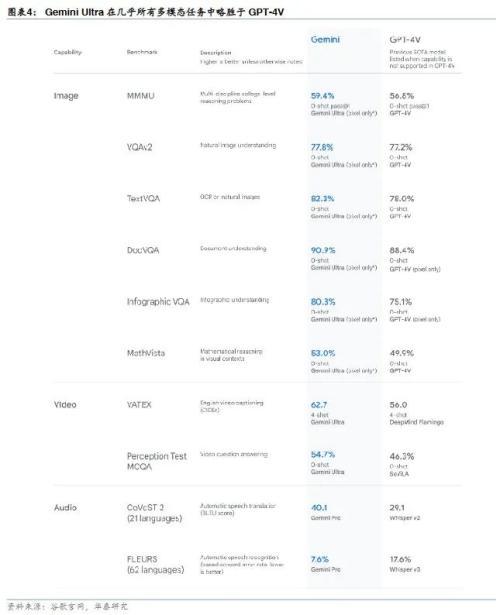
根据Gemini Technical Report,Gemini Ultra在32个基准中的30个基准中实现SOTA,包括12个流行的文本和推理基准测试中的10个、全部9个图像理解基准测试、全部6个视频理解基准测试以及全部5个语音识别和语音翻译基准测试。与其他领先的大模型相比,Gemini Ultra在绝大部分文本和推理测试中略胜于GPT-4,在几乎所有多模态(图像、视频、音频)任务中略胜于GPT-4V。Gemini Ultra是第一个在MMLU(大规模多任务语言理解)上超过人类专家表现的模型,MMLU 综合使用了数学、物理、历史、法律、医学和伦理等 57 个科目,可用于测试模型对于人类世界的知识储备和解决问题的能力。
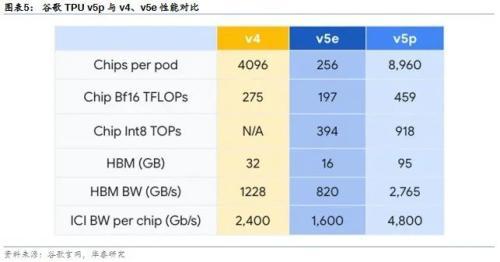
谷歌发布下一代TPU v5p
Gemini使用TPU v5e和TPU v4训练,谷歌此次同时发布下一代TPU v5p。与TPU v4相比,TPU v5p训练大语言模型快2.8倍,HBM增加约2倍(95GB vs 32GB),单个pod芯片翻倍以上(8960颗 vs 4096颗)。我们认为基础大模型是少数玩家竞争的领域,算力、数据、算法缺一不可。


风险提示:
AI技术落地不及预期。虽然AI技术加速发展,但由于成本、落地效果等限制,相关技术落地节奏可能不及我们预期。
本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。
本文源自券商研报精选