Google最强大的大模型Gemini发布了,陆续读了技术报告和一些评测/分析,周末记录和分享一下:
一、几点值得Mark的笔记
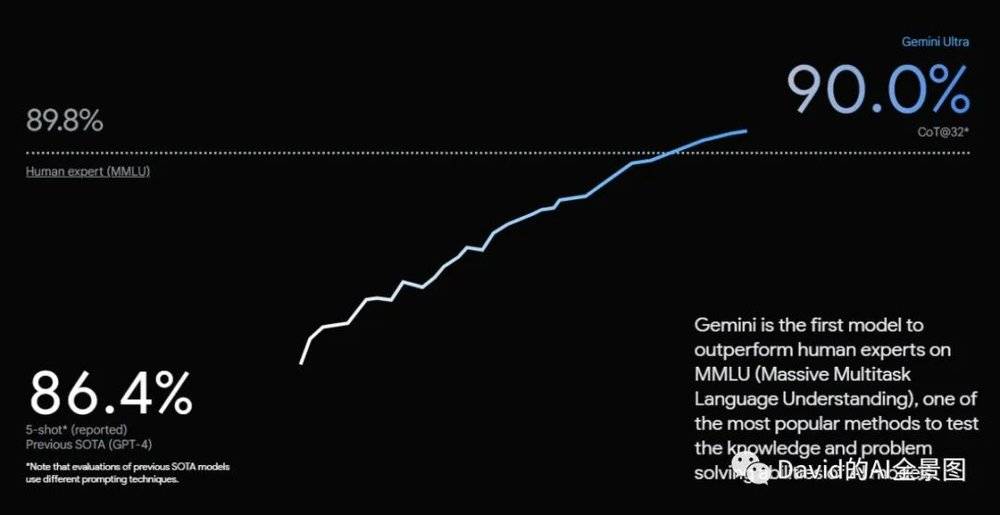
Gemini Ultra的得分为90.0%,是第一个在MMLU(大规模多任务语言理解)上超过人类专家的模型,类似于高考。国内外也有类似的评测基准。
比如
C-Eval/CMMLU/GaoKao/LucyEval/SuperClue/OpenCompass/FlagEval等等。
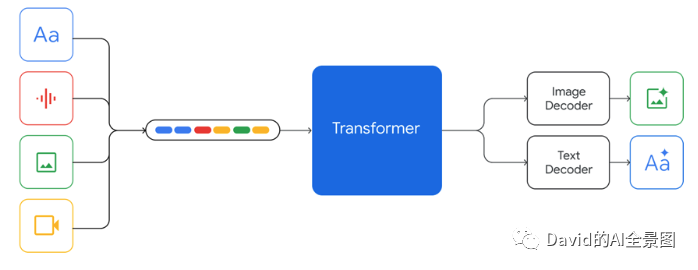
2. 此次Google对Gemini宣传突出的最大亮点——多模态。“Gemini设计成原生的多模态,从一开始就在不同的模态上进行预训练。助于Gemini从头开始无缝地理解和推理各种输入,远远优于现有的多模态模型——其能力在几乎每个领域都是最先进的。”

遵循 next token prediction 的方式,Gemini 把多模态数据从头训练,包括文本、图片、音频、视频等,所有模态数据转换为 token,最后变成一维线性输入(不同的模态按照颜色顺序标记),让模型预测 next token。
3. Google一口气发布了三个规格的模型:Ultra是最大的,对标GPT4和4V、还没有开放(12月13日开放API)。Pro对标GPT3.5,在美区Bard上可以用(我试了下我的Bard,还是之前的LaMDA)。Nano是小模型,在谷歌的Pixel 8手机上可以用。

4. 技术报告中,Google强调了算力优势:“我们宣布迄今为止最强大、高效和可扩展的TPU系统——Cloud TPU v5p ,旨在训练尖端的人工智能模型。”
翻译成大白话,就是:微软/OpenAI/Anthropic这些公司,利润(据说70%)都被Nvidia吃了,我的利润还是自己的。(其实微软和OpenAI也在尝试自己做芯片,只是进度慢于Google。)
5. Gemini语音识别在主要语种上有大幅提升(Bleu值比OpenAI的Wisper 2高10个点,但在其他语种上Wisper更强。机器翻译能力在WMT2023的测试集上评测的结果,也比GPT4略高)。
二、一个简单的评测
没用视频,用这张图试了下一些有多模态能力的模型。方法是:上传这张图,然后问:从设计上看,图中哪个车会跑得更快?