
作者 | 高佳 李维
创意 | 李志飞
1948年,英国医生罗斯·阿什比受精神病患者的启发,发明了一种古怪的机器——“同态调节器”,并宣称,这台造价约50磅的装置,是“迄今为止人类所设计出的最接近人工大脑的事物。”
“同态调节器”把 4 个英国皇家空军用于二战的炸弹控制开关齿轮装置作为底座,上面套有4个立方铝盒,4个铝盒顶部的4个小磁针是这台机器唯一可见的运动部件,像指南针一样在小水槽内摆动。
当启动机器时,磁针会受到来自铝盒的电流影响而运动,4个磁针始终处于敏感且脆弱的平衡状中。同态调节器的唯一作用,就是让4个磁针保持在中间位置,即让机器感到“舒服”的状态。
阿什比尝试各种让机器“不舒适”的方法,如颠倒电线连接的极性、颠倒磁针方向等,但机器总能找到适应新状态的方法,并重新将磁针摇摆到中心位置。按阿什比的说法:机器通过突触“主动地”抵御了任何扰乱其平衡的尝试,执行“协同活动”以重新获得平衡。
阿什比相信终有一天,这样一个“简陋的装置”会发展成一颗“比任何人类都强大”的人工大脑,去解决世界上一切复杂棘手的问题。
尽管阿什比对今天的 AGI 进化毫无所知,尽管 4 个小磁针作为传感器对智能所需的条件堪称笑谈,但它从元逻辑上挑战了所有人对“智能”的理解——“智能”不就是从环境中吸收多种模态的信息,并根据反馈修正行为、处理任务的一种能力吗?
从古怪的“同态调节器”到75年后的今天,号称多模态任务处理能力首次超越人类的 Gemini ,通过多模态原生态大数据的注入,向着数十亿年碳基智能的演化加速迭进。
今天机器智能的进化速度已远超我们想象。
一年前,OpenAI掀翻Google布局多年的AI大旗,以「暴力美学」筑就人类语言的通天塔。
一年后,Google 祭出 Gemini,「以暴制暴」建成人类跨模态大一统模型,成为另一个加速AGI演进的节点。
尽管发布首日Gemini 就深陷“视频demo夸张”的质疑,但不可否认的是,大一统多模态已初闪了光芒。Gemini 这位寓意善于体察、敏锐好奇的“双子星”印证了哪些能力,Google的命运齿轮将怎样转动?时间是OpenAI还是Google的朋友?多模态对于Agent和具身智能意味什么?拥有自主意识AGI的涌现基础已经具备了吗?如何看待 Gemini 对未来的启示?
01.
大模型的跨模态知识迁移能力再次被证明
对人类来说,比学习技能更重要的是知识迁移能力,可以跨越各个领域,纵深不同时空。如果机器学会了跨模态的知识迁移,更容易抵达“通用”。
今年7月,Google发布了基于大模型的机器人系统RT-2,让人们看到了通用机器人的希望。机械臂基于语言模型的“常识”可以从桌上“捡起已经灭绝的动物”,从常识推理到机器人执行,展示了跨模态的知识迁移。
12月,Gemini 这一记巨头的手笔,再次印证了大模型的跨模态知识迁移能力:语言模型的“常识”可以迁移到后续加入的其他非语言模态的训练中。
语言模型是认知智能的基础,最基本的认知智能是“常识”。
如果没有常识赋能,多模态大模型的很多落地执行是难以做到的。Gemini 把互联网上学到的这些“常识”,丝滑地迁移到下游的多模态任务中。如同 RT-2 ,通过互联网文本知识的迁移,实现跨模态的融会贯通——Gemini 可以把抽象的语言概念贯通到对听觉、视觉对象的理解,甚至与 Action 连起来,成为一个智能落地的系统。
对模型训练角度而言,相比于语言模型由海量的互联网数据训练,其下游模型(如机器人模型)可以通过知识迁移用少量的数据来训练,这种循序渐进的训练解决了困扰学术界多年的下游数据稀缺问题。
比如,为了达到视频中展示的效果(该展示引发对 Gemini 视频理解的存疑,但不影响跨模态知识迁移的讨论),Gemini 首先要有一些本体知识——它知道鸭子这一品种概念,知道鸭子一般是什么颜色,知道什么是蓝色。当它看到“蓝鸭”时,才会与人类有类似反应,表达“蓝鸭并不常见”这一“常识”。

Gemini 通过声音、视觉感知到蓝鸭的材质是橡胶,并知道橡胶的密度小于水的密度,基于这些常识和推理,当听到嘎吱声时,可以预判“蓝鸭能漂在水上”。

从 RT-2 到 Gemini,从单一模态的能力,到多模态感知智能与认知智能的「融合」,从眼耳口鼻身分离的“五感”模块,到融汇贯通的完整的数字“人”。
难道不意味着在模拟人类智能行为的道路上,模型的“大一统”才是正道?
02.
大一统多模态模型,终于优于定向优化的单模态模型
人类通过多感官整合来感知、认知、并产生情感和意识。Gemini 也在实践着多种模态输入,综合到大脑处理,再分由多种模态输出,这类模型对人类智能的全面“模拟”,正在加速进化。
以前的多模态模型训练,更像是具有单独的眼睛、耳朵、手臂和大脑的组合系统,它们的统一协调性并不强。
而Gemini所代表的方向,明显感觉大模型成为一个完整的数字人——一个手、眼、脑、口协调的硅基整体。
Gemini是第一个真正的端到端多模态。
以前,针对单一模态定向优化的模型,通常要比同时处理多个模态的模型的性能要好,大家惯用的方式是单模态模型训练。包括GPT-4,也是将不同的模态“拼接”带入整体中,而不是一个大一统的多模态模型。
Gemini 令人兴奋的特别之处在于,它从一开始就设计为一个原生的多模态架构,训练过程从一开始就穿插(所谓interleave)着各种模态的数据。如果说以前的大模型是在大脑外接入了感官或机械臂,而现在则是在身体内直接长出自己的眼、耳和手臂,可以挥洒自如。
无论是模型架构、训练过程,还是最后的呈现, Gemini 让多模态真正做到丝滑融合。
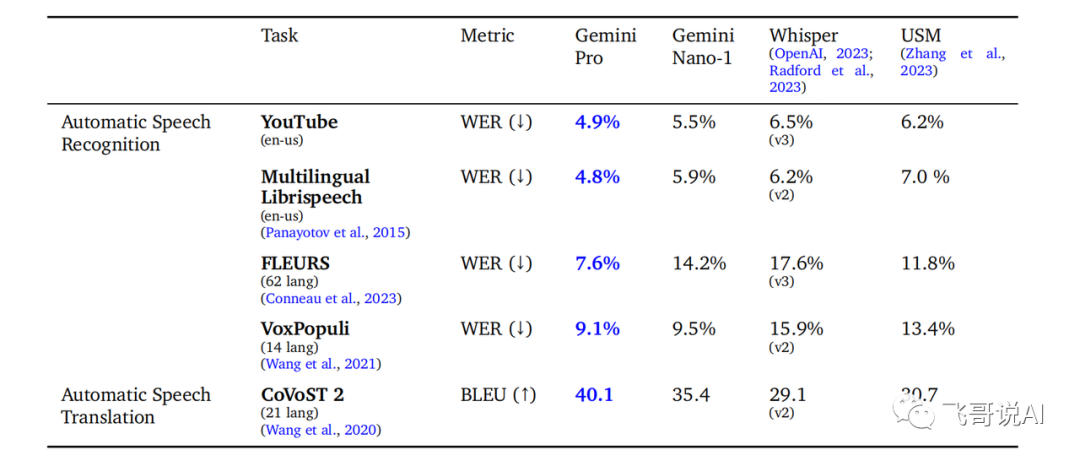
Gemini 第一次让我们看到一个大一统模型可以搞定所有模态 ,而且比专注某一个模态的模型的性能还好!比如,相较于专门为语音识别而优化的Whisper模型,Gemini 在准确率上明显提升。
这意味着多模态大一统时代的曙光到来。
其实,Gemini 不是第一个验证了各模态之间可以互相帮助提升性能的模型。这一点在 PaLM-E 也有体现,“在不同领域训练的PaLM-E,包括互联网规模的一般视觉-语言任务,与执行单一任务机器人模型相比,性能明显提高”。
另一个模态之间可以互相增强的例子,是大语言模型的多语言处理能力。如果把国际上的不同语言视为不同的细分“模态”,语言大模型的实践证明了所有语言的原生态数据的统一处理(tokenization及其embedding),共同成就了人类语言通天塔的建成。
压倒性的英文海量数据在语言大模型中的训练,同样惠及模型对其他样本较少语言的理解和生成,语言知识的迁移一再得到证实。
就像一个人精于网球技艺,也能触类旁通地提高壁球或高尔夫的能力。
自今年2月份大模型火爆以来,很多人逐渐产生了“大一统多模态模型将会超越单一模态模型”的信仰,但这一信仰始终没有得到大规模实践的证实,而这次 Google 的 Gemini 展示了信仰实现的前景,也让更多人重塑并坚定了这个信仰。
未来,单独做语音识别、机器翻译等专有识别模型可能已没有太大的意义,很多生成类任务如TTS、图片生成等,也将被大模型一统化。有人可能会抱怨大模型太贵太慢,不一定适合所有应用,但成本和速度更多是工程问题,实践中我们可以通过蒸馏大一统的多模态模型到具体的模态或场景。
我们坚信,大一统的跨模态大模型将成为实现AGI的主流通道。
进一步拓展,“模态”也不仅是声音、图片、视频等,嗅觉、味觉、触觉、温度、湿度等感知器也是一种获取环境信息的不同模态手段,都是大一统模型会囊入其中的对象。
终其要义,各种模态不过是“信息”的载体,是一种渲染、一种呈现形式、一种智能体与这个物理世界交互的手段,而在大一统模型的眼中,所有的模态究其内部都可以由统一的多维向量表示,从而实现跨模态的知识迁移及其信息交叉、对齐、融合和推理。
当各模态的壁垒被击穿,剖开各种渲染的核心,我们看到认知的起点——语言。
03.
语言是大一统模型里的核心和主线
在我们想象的AGI系统里,其核心和主线是视觉还是语言呢?有人认为是视觉,但我们更相信语言才是核心。
斯大林在他的语言学著作里曾经说过:“任何低级的生物,都有自己的语言”。
但无论它们有多少层次的变化,都不是真正的语言。真正的语言是人类所独有的,包括发明的文字、符号以及主观赋予的意义,然后通过组合形成无数种表述,载了人类千万年来的认知演化和知识积淀。
语言是认知的起点和源泉,人类的语言信息中蕴含了人类高度抽象的认知能力,而音频、图片和视频则更加感性,表示的是人类的情绪和具象能力,更偏向于捕捉人类的感知能力。
当人类学会了认知,加之音频、图片和视频等更加感性的表达感知的能力,从感知到认知,从情绪到逻辑,这才是我们人类的大脑状态。大一统多模态也一样,在信息的处理和推理过程中,当鸿沟被填平,融会贯通是自然结果。
在 RT-2 和 Gemini 中,语言都占据了主线。
比如在 RT-2 中,代表语言模态的参数规模和数据量都远远大于下游的图片和动作模态。
我们预测,在未来任何AI系统里,不管是不是语言任务,都会把语言模型作为一个基础模型和训练的起点,然后加入其他模态或任务的数据继续训练,都会在某种程度上继承语言模型强大的认知能力。
如果这一点真正做到了,也许这是语言模型对AI最大的贡献,因为它真正实现了研究人员对它的初心和定位——Foundation Model.