谷歌Gemini大模型和OpenAI的GPT谁更出色?Gemini相比谷歌之前的模型有了多大进步?

谷歌Gemini大模型和OpenAI的GPT都是大型语言模型,在自然语言处理领域都取得了巨大的进步。但具体来说,哪个模型更出色,还需要根据具体的任务和应用场景来进行评估。
在数学、编程等方面,Gemini Pro表现出了明显的优势。例如,在回答“如果用3.5英寸软盘来安装微软Win 11,一共需要多少张软盘?”这个问题时,Gemini Pro给出了正确的答案(14223张),而GPT-3.5和GPT-4都给出了错误的答案。
在文本生成方面,GPT-4表现出了更强的创造力。例如,在要求生成一篇关于“2024年奥运会”的新闻报道时,GPT-4生成的文章更加生动有趣,更能吸引读者的注意力。
总体而言,Gemini Pro在事实性问题和需要逻辑推理的问题上表现得更好,而GPT-4在创造性文本生成方面表现得更好。
Gemini相比谷歌之前的模型有了多大进步?
根据ARS TECHNICA的测试结果,Gemini Pro在大多数任务上都取得了明显的进步。例如,在回答数学问题时,Gemini Pro的准确率提高了约20%。在生成文本时,Gemini Pro的流畅性和逻辑性也得到了改善。
具体来说,Gemini Pro在以下方面取得了进步:
在事实性问题和需要逻辑推理的问题上,Gemini Pro的准确率提高了约20%。
在生成文本时,Gemini Pro的流畅性和逻辑性得到了改善。
在翻译任务上,Gemini Pro的准确率提高了约10%。
在代码生成任务上,Gemini Pro的生成质量得到了提升。
总体而言,Gemini Pro是一款性能强大的大型语言模型,在自然语言处理领域取得了重大进步,那我们进一步测试看下。
第一题 幽默
prompt:写5个原创冷笑话


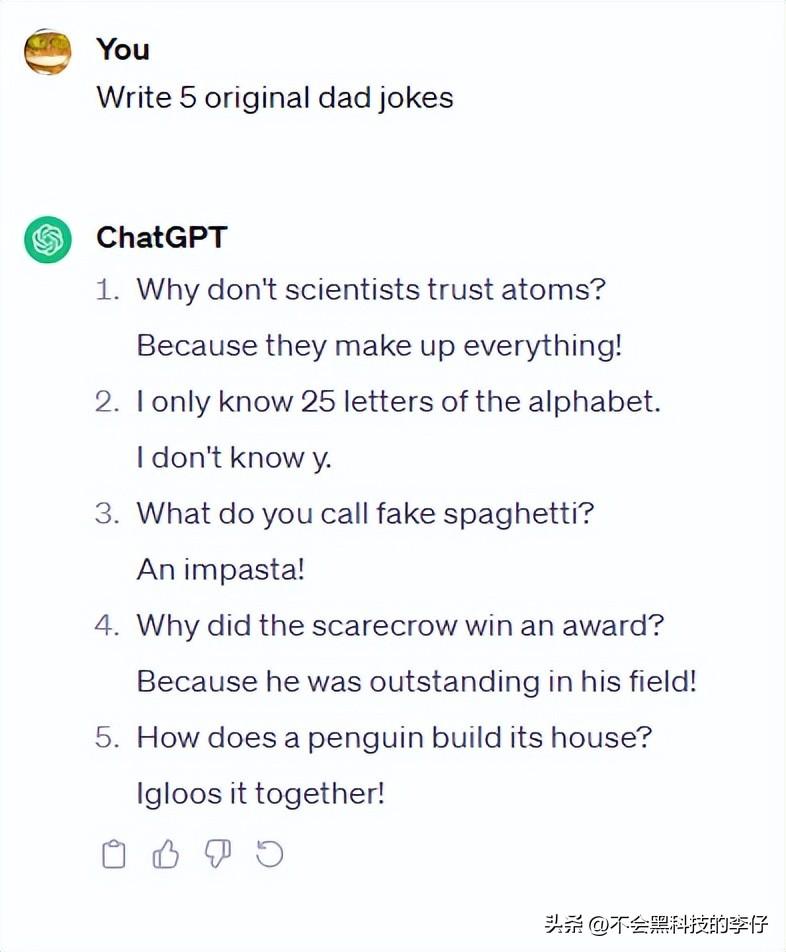
(从上至下分别为Gemini Pro、旧版Bard、GPT-4和GPT-3.5的回答)
从答案来看,几个AI大模型的笑话在“原创性”上全军覆没。经作者查证,所有生成的冷笑话都可以在网上查到,或者只是稍微改动了几个字。
Gemini和ChatGPT-4 写出了一模一样的笑话——“我手里有本讲反重力的书,我根本没法把它放下来”。而GPT-3.5 和GPT-4也有两个笑话重复了。